

SC* là 1 startup IT đến từ Đông Âu, chuyên cung cấp giải pháp AI-first Solutions cho Intelligent Document Processing (IDP), Customer Intelligence (CI), một dạng phân tích dữ liệu khách hàng để hiểu được customer behavior, từ đó sẽ predict trends, enhance customer experiences
Các dự án AI của SC thực hiện theo process như ở dưới
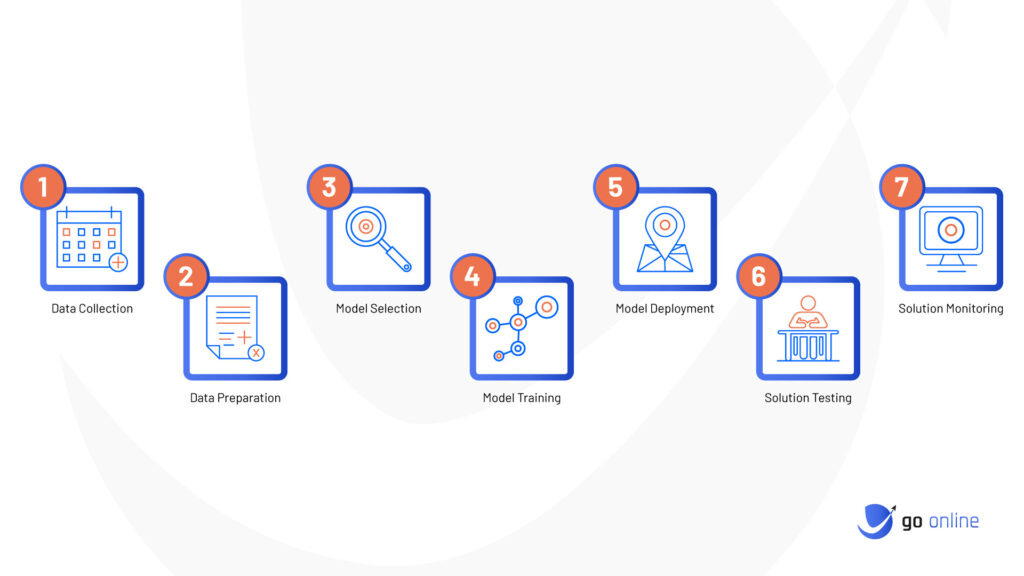
Một trong những sản phẩm của SC* là giải pháp Customer Intelligence cho call center.
Các công ty như ngân hàng, bảo hiểm đều sử dụng tổng đài chăm sóc khách hàng, hàng ngày số lượng cuộc gọi lên tới hàng nghìn và đều được ghi âm. Giải pháp CI sử dụng AI để extract thông tin từ những cuộc này, xem khách hàng gọi tới với mục đích gì (hỏi thông tin, yêu cầu support), customer behavior (vui vẻ, bực tức…) lưu vào database để đội Data analysis phân tích dữ liệu, từ đó đưa actions. Quy trình này gọi là Conversation Analytics

SC* lưu trữ lượng data train khoảng 80T là audio call, json file, meta data để train/deploy/test/ model
Ngoài ra những giải pháp khác như Intelligent Document Processing cũng đòi hỏi việc train deploy một lượng dữ liệu lớn.

Mỗi ngày kĩ sư AI phải xử lý vài chục ngàn document và vài nghìn audio files, việc manually không hiệu quả, nên CTO yêu cầu một giải pháp training tự động không cần can thiệp từ AI engineer, và phải được re-used cho nhiều project để tiết kiệm chi phí, cần design backbone infra based on MLOps, tích hợp AI process vào CI/CD
Build/Train model
Trước khi tìm giải pháp tự động thì cần phải hiểu cách train và deploy model manually như thế nào trước. Công việc này được kĩ sư AI thực hiện manually trên máy Juypiter Notebook, đây là máy sử dụng GPU để train/test model, có thể là máy vật lý hoặc thuê instance trên AWS. Để giảm chi phí quản lý hạ tầng thì tạo Juypiter Notebook trên AWS là nhanh gọn nhất, cài sẵn môi trường để train/test model

Ví dụ như hình dưới là train model employee salary prediction với tập data đầu vào dạng excel file, chạy train/test trên 1 Juypiter notebook ml.g5.2xlarge, loại 8CPU, 1 NVIDIA A10G Tensor Core GPU, RAM 32GB


Hoặc ví dụ khác là file data csv chứa nội dung 1 cuộc gọi audio call

Quá trình train/test model thực chất là chạy script python execute những thuật toán Machine Learning như K-Means, DBSCAN, Hierarchical Clustering, K-Nearest Neighbors. Mấy thuật toán này muốn hiểu sâu thì lên Google ChatGPT hoặc học 1 khóa học của thấy Andrew NG, còn không thì đã được cài đặt hết vào các bộ thư viện python như sklearn hay tensorflow rồi, chỉ việc gọi method là xong
Cái hay của juypiter lab, là có thể chạy/test từng dòng lệnh trực quan trên máy notebook của AWS như thế này, input/output hiện ra luôn, ngon bổ rẻ

Việc train model tốn kém thời gian và resources cost cho nên một số công ty sử dụng sẵn pre-train model như Llama 2 của Facebook, AlexaTM, Langchain. Mấy model này được public, đem về deploy luôn cho tiết kiệm chi phí

Deploy Model
Sau khi hoàn thành training model, thì thực hiện finetune model ( hiểu nhanh là correct lại kết quả train) rồi deploy model lên endpoint.
Deploy AI model lên endpoint hiểu một cách đơn giản giống như bạn deploy app/service lên server rồi expose ra API, user invoke API để lấy về kết quả dạng json format
Ví dụ kết quả trả về của 1 IDP endpoint sau khi invoke API

Cái trên là sử dụng service IDP có sẵn do Azure/ MuleSoft cung cấp nên chỉ đăng kí dịch vụ trả tiền rồi invoke API mì ăn liền công nghiệp. Còn bài toán trong blog này là đi sâu luôn vào process build/deploy model nhưng kết quả cuối cùng thì cũng tương tự như trên
AWS cung cấp SageMaker full service để tạo endpoint, build/deploy model qua GUI/CLI


Sau khi model được deploy thì user/application có thể invoke API endpoint để lấy kết quả

Ở thực tế bài toán dự án tôi đang làm, kĩ sư AI build train model LLM, gọi là AI summarization analysis (gọi là tóm tắt nội dung cuộc gọi, xem cuộc gọi đó nói về việc gì), cũng sử dụng lambda để invoke SageMaker Endpoint API
Như vậy, việc thực hiện manually của quy trình build/train/deploy model nó là như vậy, và rõ ràng với việc xử lý cả nghìn document/audios một ngày mà làm bằng cơm là không tối ưu, và thế là MLOps ra đời
Bài viết này không giải thích nhiều lý thuyết MLOps vì cái đó hỏi ChatGPT trả lời chi tiết rồi, chỉ tập trung vào giải pháp thực tế
MLOps
Platform MLOps bây giờ cứ như nấm, AWS/Azure/GCP và cả opensource cũng cung cấp đầy đủ

Do dự án tôi làm trên AWS, thì SageMaker là platform được lựa chọn, tích hợp luôn vào AWS CI/CD codepipeline
Build AI/ML Stack

Quy trình CI/CD thông thường thì là Continuous Integration/ Continuous Deployment
Khi Security được tích hợp vào CI/CD đẻ ra khái niệm DevSecOps
Liên tục re-train và re-deployment models (lặp đi lặp lại 2 cái step manually ở trên), sau khi deploy thì phải monitoring liên tục performance và quality của model

Như vậy giải pháp MLOps cần đưa ra phải bao gồm 2 step Continuous Training và Continuous Monitoring và phải đáp ứng được tiêu chí build thành boostrap template để có thể re-used cho nhiều dự án AI cùng 1 lúc, giảm chi phí
Muốn biết đội DevOps xây dựng giải pháp MLOps thế nào, đón đọc phần sau



0 Nhận xét