
Thập Đại Báo Thủ DevOps - Tập 1

Nghề IT lúc thịnh lúc suy
Nhưng báo thủ đời nào cũng có
Ngày xưa các cụ có nói rằng “Không sợ địch mạnh chỉ sợ đồng đội ngu” để ám chỉ những thanh niên bóp trym đồng đội, xiên ass đồng môn. Từ thời Thần Điêu Đại Hiệp, báo thủ Quách Phù chém cụt tay Dương Quá, làm Tiểu Long Nữ bị thương rơi xuống hàn đầm, đến thời IT 2024, Devoper lỡ tay xóa data, public cloud credentials lên Github, destroy K8s cluster, code bug đốt tiền infra, gây ra đủ tình huống dở khóc dở cười, khiến team mate khóc ra tiếng mán. Một số tính huống thuộc về human mistake, thật sự khó tránh khỏi. Tuy nhiên cũng có những case siêu báo, gọi là ăn hại…
Dưới đây là thập đại báo thủ thời nay, tên tuổi được lưu danh sử sách, khắc bia trên Quốc Tử Giám để đời đời các thế hệ DevOps nhớ tới, rút kinh nghiệm
10. Reboot server

Ngày Dần , Tháng Mão, Giờ Sửu… Dự án X
Các thanh niên đang làm công việc operation hệ thống, anh A chạy salt-run để tiến hành cài đặt application, chị B chạy script collect log data, write to DB, cuộc sống yên bình lặng lẽ… Anh PM ơi, session của em tự nhiên bị terminate Chị Lead oi, script của em đang write DB thì bị treo cứng rồi Ổ Data volume mount tự nhiên biến đâu mất rồi Tiếng í ới vang lên trong room, dần dần biến thành tiếng chửi rủa, la ó… Bỏ mẹ rồi anh ơi, con máy Linux của em nó chậm nên em tiện tay sudo reboot, mà quên mất em đang trong terminal của Server Thôi xong bóp z*i rồi,
Anh em làm IT thì hết giờ làm việc là shutdown PC, thỉnh thoảng máy lag chậm, tiện tay command line reboot là xong, ngon bổ rẻ, đấy là máy cá nhân. Còn thực tế các server production việc reboot-shutdown cần phải được thực hiện theo quy trình rất nghiêm ngặt gọi là Reboot Sequences, bởi vì nó ảnh hưởng đến down time, backup data, system incosistency. Ví dụ một process đang chạy write data vào DB, khi server reboot, process bị exit làm quá trình update DB bị gián đoạn làm data incosistency Ngoài ra, các server trên cloud đều được mount vào EBS volume chứa data, các volume này được encrypt dùng tool như LUKS hay Bitlocker (Windows), mỗi khi server reboot, phải thực hiện process re-mount lại chứ không đơn giản là auto-mount Như vậy quá trình start/shutdown production phải graceful shutdown bao gồm shutdown các application, process background, chọn maintenance windows vào lúc không có user access (Activate notification process, thông báo cho user) và Flush disk writes: Ensure that all disk writes are completed before rebooting.
Tóm lại process reboot server rất phức tạp không đơn giản là sudo reboot là xong
Đối với tập đoàn lớn như Facebook, Google cụm server cả trăm, data center rải khắp thế giới, để đảm bảo không impact người dùng, họ sử dụng Rolling Reboot , gọi là reboot từng cụm server một, để đảm bảo lúc nào cũng có server running để serve request từ người dùng, giữ hệ thống đạt High Avaialbiity
9. terraform apply --auto-approve

Infra as Code giúp việc provisioning infra hoàn toàn tự động tích hợp vào CI/CD, loại bỏ human misktake. Tuy nhiên chạy script tự động approve khi chưa review kĩ terraform plan gây ra hậu quả là lỡ tay destroy resources trên cloud
Bởi vì một số resources như RDS không thể rename mà phải destroy rồi tạo ra instance khác với tên mới. Anh anh ngồi đọc code terraform thấy cái naming của RDS thấy ko ưng trym lắm, muốn đặt một cái tên mới nghe cho uy tín thể là chỉnh code rồi auto-approve để ra ngoài ăn trưa cho nhanh, Cơm no rượu say xong về check logs thấy con RDS hiện tại bay đâu mất, thì ra đã bị terraform nó destroy mất rồi
Cũng may chỉ là môi trường Dev nên import lại dữ liệu là xong, còn trên PROD, có bước approval gate trên CI/CD chỉ cho phép manual review nên độ báo chỉ ở cấp 9
8. rm -rf
Ngày Dần , Tháng Mão, Giờ Sửu… Dự án Y
Anh SRE ssh server để thực hiện công việc quản trị như thường ngày.
Chết mẹ, ổ data sao empty thế này, dữ liệu bay đâu hết
History log lúc xxx-yy-zz câu lệnh rm -rf *
Câu lệnh quốc dân dùng để xóa dữ liệu, được sử dụng khi cần clean up , free disk space với tham số được truyền là path of folder
Câu lệnh này được đặt trong Bash Script hoặc clone jobs để thực hiện clean up dữ liệu thừa như log /tmp folder để dọn dẹp ổ đĩa. Script được trigger bằng tay hoặc tự động theo schedule hoặc khi có alert về disk space
Tuy nhiên, gặp tình huống thanh niên tay nhanh hơn não, chạy script nhưng không đọc kĩ hướng dẫn trước khi dùng, run script mà truyền sai tham số, hoặc sử dụng tham số default ( thư mục hiện hành) nó vô tình đã xóa sạch dữ liệu trên server
Tất nhiên, data đều được backup nên có thể lấy bản backup latest rồi restore lại dữ liệu là OK, nhưng mất thời gian, ảnh hưởng đến user , và một lượng data có thể mất vĩnh viễn nếu không có bản backup tương ứng
Tương tự của rm -rf thì SQL delete table, xóa record cũng làm mất dữ liệu trên DB, phải mất công recover lại.
7. Destroy K8s cluster
Hệ thống của dự án X có vài chục K8s cluster trên mỗi môi trường Dev,QA, UAT, Prod, deploy application như Jenkins, monitoring, business application etc…
Rancher được sử dụng để quản lý cluster, Admin có thể quản lý cluster thông qua GUI hoặc rancher CLI khá tiện lợi.
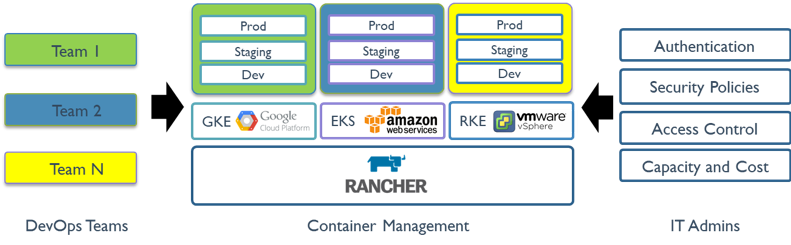
Admin dùng Rancher để provisioning K8s cluster, create/destroy k8s node, manage helm chart catalogs, projects
Nếu quản lý mọi thứ qua Rancher thì cũng ổn vì cơ chế phân quyền user/role. Một ngày đẹp trời, anh Admin đang cần xóa 1 số un-used cluster để dọn dẹp, saving cost
Tự nhiên Rancher hôm nay bị trục trặc access toàn 502, log ticket cho SRE fix chờ dài cổ không thấy kết quả, sốt ruột sẵn tiện access luôn GCP GKE xóa cho nhanh,
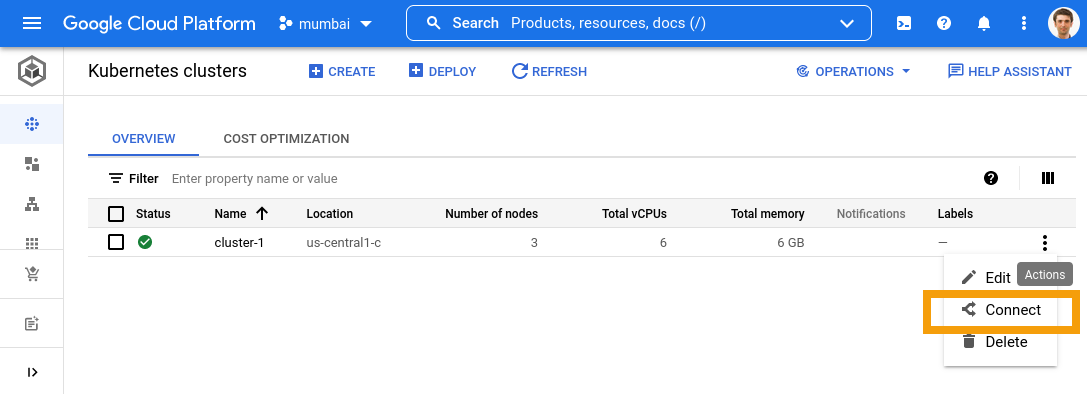
Cluster xóa thì nhiều, tiện tay click check box rồi bấm delete một thể, GCP yêu cầu gõ tên 1 cluster để confirm, nhanh tay gõ rồi enter
Màn hình hiện deleting,…
Thấy có gì sai sai, thôi bỏ mẹ rồi, lỡ tay check box check nhầm luôn cái cluster Jenkins CI/CD , thế này thì bóp zái rồi.
Jenkins access 502 luôn, may thay Data jenkins lưu trong GCP disk chứ ko phải là PV volume
Infra thì viết bằng IaC code nên chạy lại code rồi phục hồi dữ liệu
Mất công test kiểm tra lại jobs chạy OK không, vậy là đi luôn một buổi sáng
Đúng là ko cái dại nào bằng cái dại nào
6. Đốt tiền infra
Cái này thì có bài riêng rồi
Mấy case trên dù sao vẫn chi là human mistake, mức độ thiệt hại không quá lớn nhờ hệ thống build DR rất tốt, dữ liệu được phục hồi nhanh. Còn 5 case top đầu mới thật sự là đỉnh cao của báo thủ, để lại hậu quả nghiêm trọng, uy tín doanh nghiệp
Đón đọc phần 2



0 Nhận xét