
Tiếp tục phần 1

Đến câu chuyện là khi train model phải có công cụ để visualize và tracking quá trình train. Việc track (theo dõi) quá trình train model là một phần rất quan trọng trong quá trình phát triển mô hình machine learning (ML). Nó giúp bạn hiểu được mô hình đang học như thế nào, kiểm soát các tham số, so sánh các lần huấn luyện, và tái sử dụng mô hình sau này.
Track quá trình train model
Theo dõi hyperparameters (tham số huấn luyện như learning rate, batch size,…)
Ghi lại metrics như loss, accuracy theo từng epoch
Lưu trữ mô hình đã huấn luyện
So sánh các lần train để tìm cấu hình tốt nhất
Ghi lại metrics như loss, accuracy theo từng epoch
Lưu trữ mô hình đã huấn luyện
So sánh các lần train để tìm cấu hình tốt nhất
Hỗ trợ debug khi có vấn đề
Giải thích từng khái niệm epoch, learning rate theo cách simple nhất

Vì dụ Nếu bạn có 10.000 bức ảnh dữ liệu huấn luyện, thì 1 epoch là khi mô hình đã nhìn thấy toàn bộ 10.000 bức ảnh đó một lần, gọi là scan xong toàn bộ dữ liệu
Thường để cho nhanh thì scan theo batch, loop (iteration)
- Dataset: 10.000 ảnh
- Batch size: 100 (lấy 1 cục 100 ảnh)
- ⇒ Sẽ có 10.000 / 100 = 100 iterations / 1 epoch
Learning rate hiểu theo kiểu non-tech thế này ( Đọc google nổ não)

Bạn tập leo núi, nếu trèo từ từ, từng bước một thì chắc chắn, nhưng mà nó lâu
Còn muốn nhanh chóng thì trèo nhanh, bước dài ra, nhưng sẩy chân cái là lộn cổ
Nhưng vậy học chậm quá thì lâu tốn time, mà nhanh quá thì thành nhanh nhẩu đoảng, phải điều chỉnh một learning rate sao cho hài hoà, vì cái gì quá thì cũng không tốt. Tóm lại là mô hình điều chỉnh các trọng số để đạt kết quả tối ưu
Vậy điều chỉnh trọng số hiểu 1 cách đơn giản là thế nào
Tham số trong LLM model giống như mình chỉnh tham số của Đài Radio, dò kênh , tần số cho đến khi nào nghe rõ thì thôi, mà muốn rõ thì chỉ có ngồi chỉnh chỉnh experiment thôi. LLM cũng vậy, khi train model thì phải điều chỉnh các tham số để output hợp lý nhất (LLM có đến cả tỉ tham số)
Rõ ràng khi phải điều chỉnh liên tục bằng experiment như vậy mà không track/monitor thì bó tay. Đại loại là ngồi ghi lại kết quả thống kê
Công cụ để monitor training model, đội dự án list out 3 tool thông dụng nhất và dễ tiếp cận
- Wandb (Weight & Biases)
- TensorBoard
- Đánh giá 3 công cụ thì Wandb là chất lượng uy tín nhất, mặc dù là commerical, viết tắt của Weight and Bias ( 2 tham số của AI)
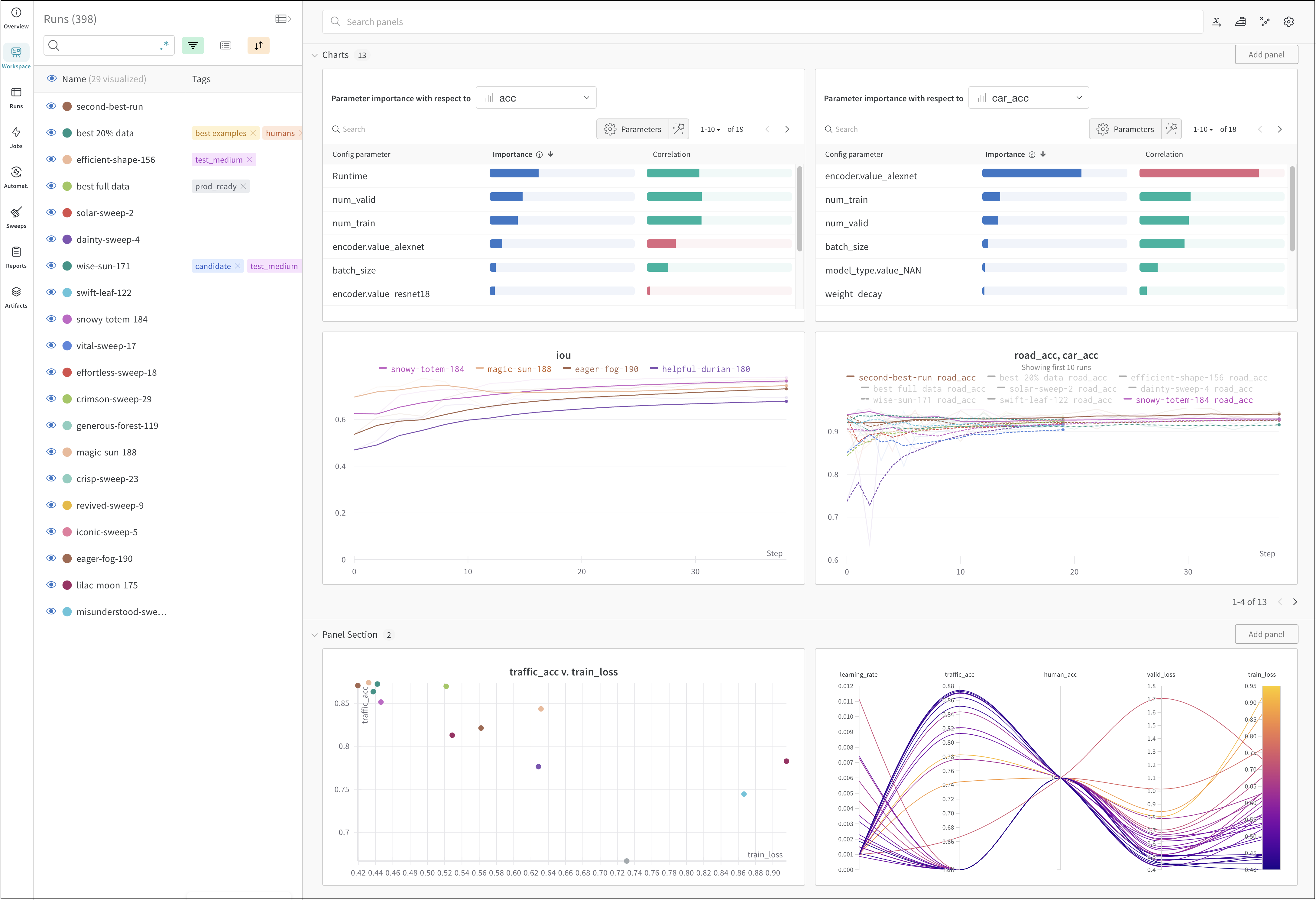
Wandb là SaaS nên chỉ cần đăng ký account, make payment và tạo project là xong.
Như đã giải thích ở phần 1, training model là quá trình execute code với input là các dataset. Để collect được metrics từ training process, kĩ sư AI sẽ nhúng code xử lý đẩy metrics vào
Khởi tạo project
wandb.init(project="ai-markers", entity="mcg", name=exp_name, config={"fin": fin, "num_classes": num_classes, "N": N, "BATCH_SIZE": BATCH_SIZE, "LR": LR, "EPOCHS": EPOCHS, "CLASS_WEIGHTS": class_weights.tolist(), "SEG_WEIGHT": seg_weight, "OFFSET_WEIGHT": offset_weight, })Rồi log metrics ra wandb
wandb.log({ "epoch": epoch + 1, "learning_rate": current_lr, "train_loss": train_loss, "train_seg_loss": train_seg, "train_off_loss": train_off, "train_accuracy": train_accuracy, **val_metrics })Trong đoạn code trên thì epoch và learning_rate đã giải thích, còn khái niệm train_loss và train_accuracy, hai cái này search Google đầy, nhưng đọc hiểu thì hơi bị căng

Giải thích non-tech theo kiểu giaosucan’s blog thì thế này
Training model giống như quá trình dạy một em gái làm bài trắc nghiệm. Em ý làm sai nhiều câu tức là train_loss cao, em ý làm sai lắm tức là ông dậy học có vấn đề, cho nên phải xem lại cách dậy học để sao cho em ý loss càng thấp càng tốt. Đây chính là mục tiêu của AI
Lúc mới học, AI “làm sai” nhiều →
train_loss = 5.0 mỗi lần sai thì cốc trán cho em ý tỉnhHọc dần, ăn cốc nhiều nên em ý hiểu bài hơn →
train_loss = 0.5 giảm dầnNgược lại của train_loss là train_accuracy, tỉ lệ làm đúng. Làm đúng nhiều thì accuracy cao, đó là mục địch của train AI luôn
Thì nhờ có Wandb nó tracking thông số thì mới điều chỉnh phương pháp dạy học cho đúng được
Trong quá trình training, mọi metrics đều được lưu lại trên wandb, nên đội dự án mới tuỳ chỉnh các tham số đầu vào của training để huấn luyện mô hình với kết quả tốt nhất, và lưu model có kết quả tốt nhất
Bên cạnh Wandb thì tensorboard và MLFlow cũng là một lựa chọn low cost. Đặc biệt MLFlow là self-host solution, khi đội dự án tự build hẳn 1 còn MLFlow tracker server để collect dữ liệu training
Ngoài ra nếu MLFlow server cũng tích hợp sẵn với SageMaker, nên có thể dùng em nó đi kèm với giải pháp AI




0 Nhận xét