Câu chuyện

Các hệ thống ngân hàng, bảo hiểm, internet provider đều có hệ thống call center, gọi là tổng đài CSKH. Khi khách hàng gọi điện tới call center, hệ thống sẽ record lại audio call để sau này phân tích thông tin là ông khách nào gọi tới, ông nói về vấn đề gì, tâm sinh lý ra sao vui mừng, hờn giận, nổi cơn tam bành blo bla, gọi là Customer Behavior. Ngân hàng một ngày có thể cả chục nghìn cuộc gọi, và với số lượng audio call lớn như thế thì không thể nào làm bằng cơm được.
Không chỉ có ngân hàng, mà trong ngành hàng không, các đoạn nội dung trao đổi giữa phi công và trung tâm điều hành bay đều được record để phân tích (Air Traffic Control Communication)
Thế là họ apply công nghệ ASR (# Automatic Speech Recognition), dịch tín hiệu lời nói thành văn bản.
Bài viết này mô tách cách mà ASR được 1 công ty startup của US sử dụng khi giải bài toán trên
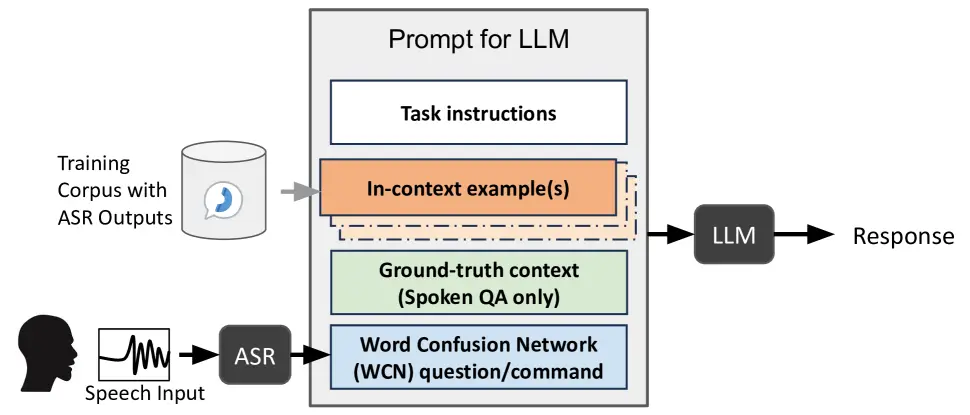
Nói sơ sơ về hệ thống Speed Recoginition
Speech recognition (Nhận dạng lời nói): Là quá trình xác định các từ trong câu nói và chuyển đổi chúng thành định dạng máy tính (Text)
Chú ý là cái này khác với Voice Recoginition vốn được dùng trong authentication
Công nghệ ASR có từ lâu, từ những năm 70 do IBM phát triển, nhận dạng được độ 16 từ và số cơ bản, tuy nhiên thì nhận biết vẫn còn rời rạc kiểu máy móc, nhận dạng kí tự , chứ không hiểu được context của lời nói. Mãi cho đến thập niên 2011 ~ 2020, khi Deep Learning phát triển cùng với sự ra đời của LLM, thì ASR mới thực sự hiệu quả
Bởi vì tiếng nói của con người khá là phức tạp với nhiều giọng accent khác nhau giọng Ấn, giọng Sing, giọng Nhật Bổn. Ngoài ra context cũng nhiều tầng ngữ nghĩa khác nhau, sắc thái ngôn ngữ rất phức tạp, ví dụ như một chàng trai gọi cho cô gái hỏi “Em đang làm gì đấy”, nghĩa đen là hỏi em đang làm gì, nhưng nghĩa bóng là thể hiện sự quan tâm, nhớ nhung, chứ không đơn giản là convert từng audio sang word
Trong mô hình này thì một số lượng lớn text data được dùng để train LLMs để nó có thể hiểu được ngôn ngữ human, LLMs model sẽ phân tích lịch sử hội thoại để đưa ra context chứ không phải kiểu dịch voice word to text một cách máy móc.
Dự án do Startup này nghiên cứu có tên là Radio Telephony Research mục đích là “Transcribe speed from radio audios” , radio record ở đây là Air Traffic Control Communication (ATCC) là giao tiếp giữa phi công và trung tâm điều hành mặt đất
Vấn đề đặt ra đối với mấy cái audio call này là việc giảm nhiễu (Denoise) bởi giọng nói của người accent nhiều, nhất là mấy ông Ấn Đụ, hoặc giọng người địa phương, nói ngọng. Ngoài ra còn tiếng ồn của động cơ cũng ảnh hưởng đến khả năng transcribe của ASR
Như vậy việc lựa chọn
dataset để trained LLM models phảiđúng với context của ATCC, ví dụ như :
"Cleared for takeoff" – authorization to depart the runway
"Hold short of Runway 27" – instructs the pilot to stop before the runway.
"Climb and maintain 10,000 feet" – instructs vertical movement.
"Squawk 7500" – emergency transponder code for hijacking.Có một số nguồn dataset chuyên dùng trong ATCC được nhóm nghiên cứu lựa chọn như
Phần Fine-Tunes models for ATCC ASR, team sử dụng Whisper Medium và Fine-Tuned dataset
ATCO2 + UWB-ATCC
Whisper Medium là open source ASR được phát triển bởi Open-AI, được trained on 680k hours dữ liệu gắn nhãn, sequence-to-sequence_ model (Seq2Seq)
Khái niệm này search Google đọc thì loạn cả chưởng, còn hiểu theo cách giáo sư cận blog là thế này
Bạn là người Việt Nam đang muốn tán một em người China, bạn không biết tiếng Trung thế nên chơi Google translate điền vài input sequence là “Anh yêu em” vào Google translate sang “Wo ai nì”
Đấy là một ví dụ của Seq2Seq, cho vào input và AI model trả về một output khác, nội dung tương tự nhưng độ dài sentence khác nhau (
Machine Translation)
Hoặc vị dụ khác, gọi là Text Summaizations, đưa input là một đoạn hội thoại dài tràng giang đại hải, và bảo AI “cho anh cái summary cái, dài dòng phức tạp quá” thế là em AI gen ra một đoan sequence summary ngắn gọn
Ngoài Model file-tines whisper, team thử nghiệm một model nữa gọi là
Wav2Vec 2.0Experiments
Sau khi đã lựa chọn được Models, bước tiếp theo là experiments, file audio được standard như sau
| File format | WAV |
| Codec | PCM_S16LE |
| Channels | Mono |
| Sample rate | 16 kHz |
| Bitrate | 256 kbps |
Tiêu chí đánh giá kết quả experiments
Trong quá trình experiments, team sử dụng tập dataset và fine-tune models nhắc tới ở trên sau đó collect results rồi lập report đánh giá theo tiêu chí trên, từ đó quyết định chọn dataset model nào
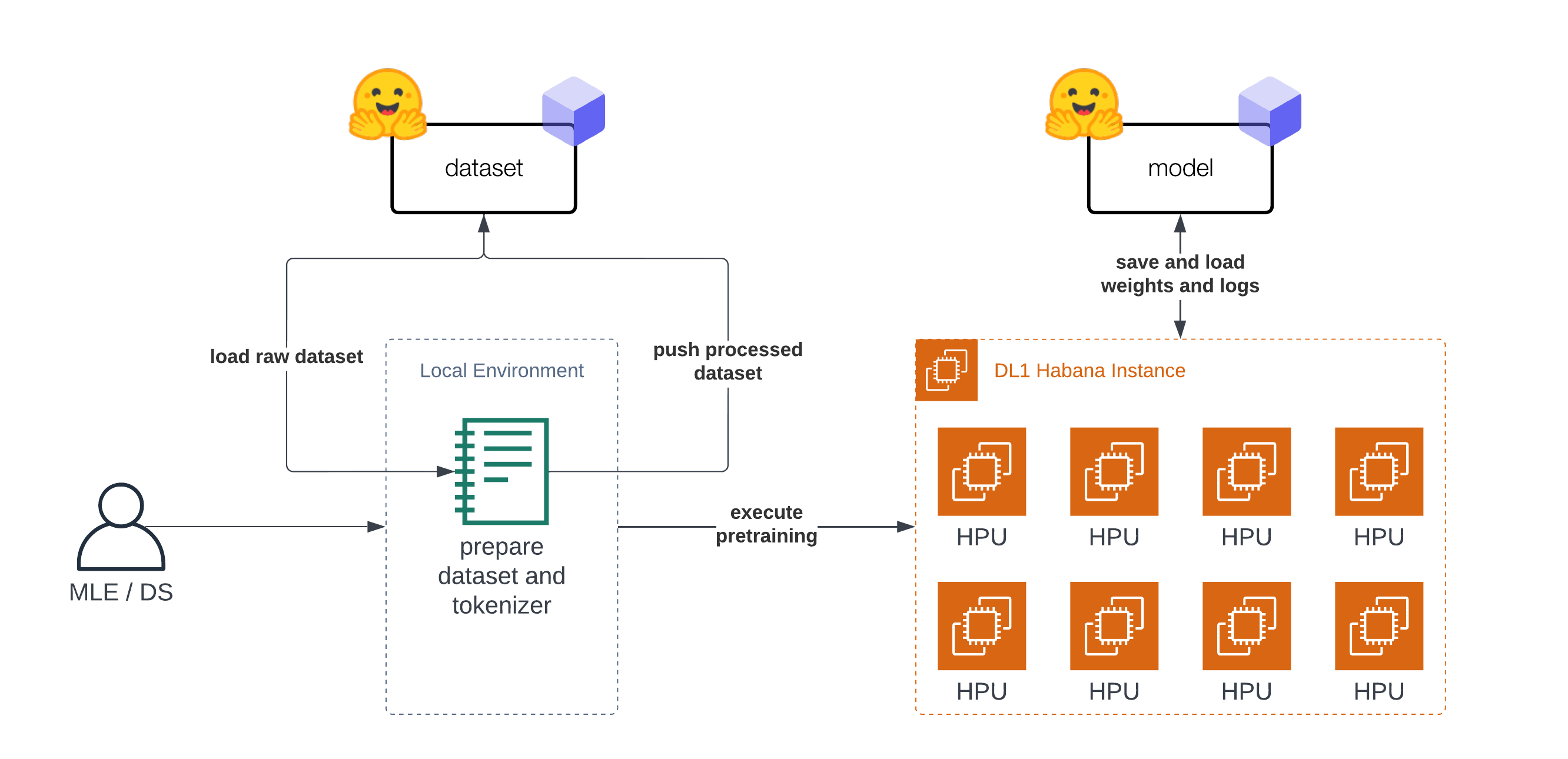
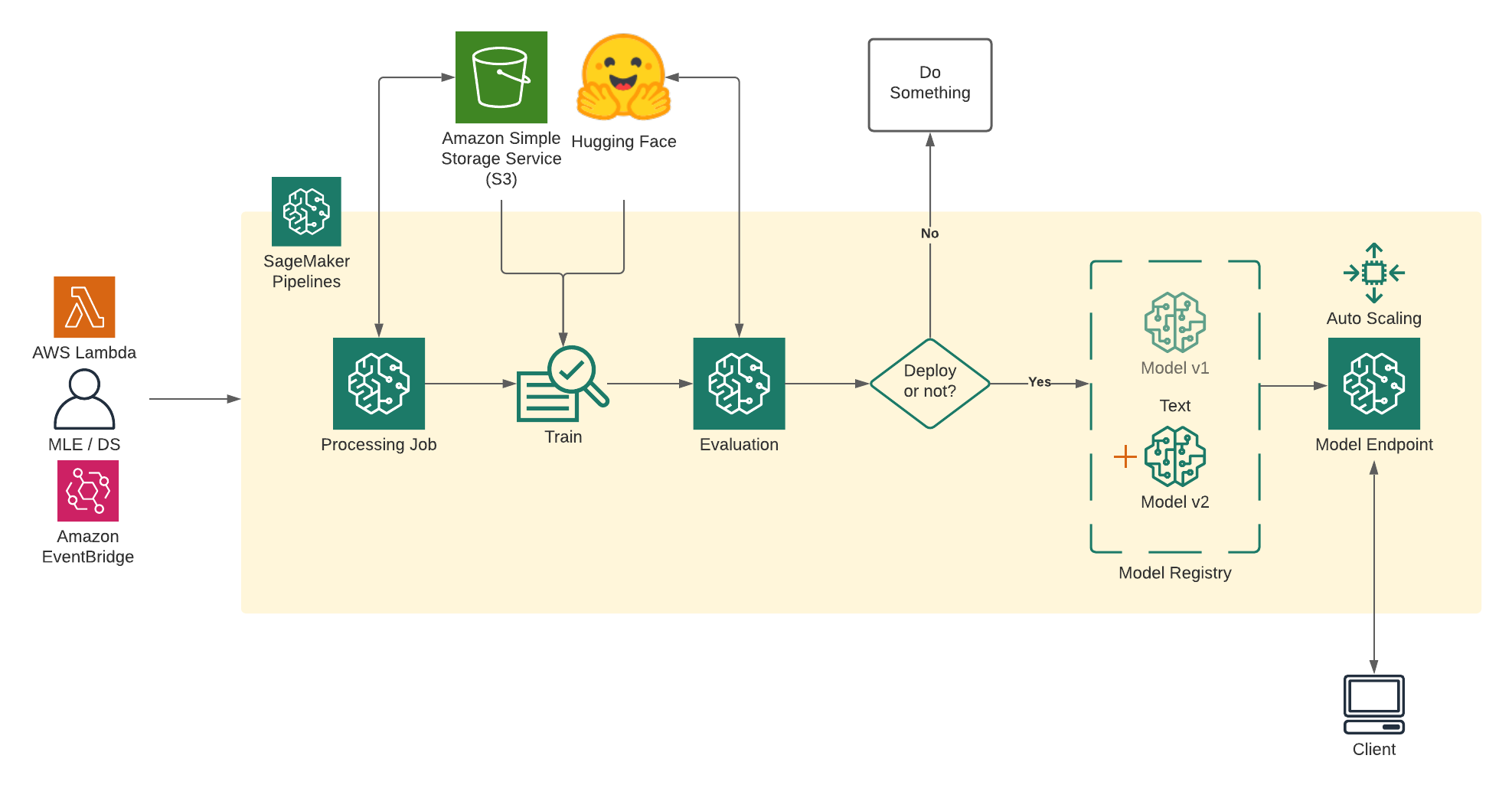
Team dự án sử dụng SageMaker Notebook là GPU instance chạy NVIDIA để thực hiện training, loại instance là g4dn.4xlarge dùng tới 64G ram, phải chạy train trong vòng 5 ngày liên tục để hoàn thành training
SageMaker là công cụ khá hay, cái này lý thuyết Google ChatGPT đầy, nên tôi không nói nhiều mà chủ yếu focus vào thực tế khi sử dụng nó
Trước hết giải thích một cách đơn giản của việc “train model” nó là thế nào. Thực chất là AI engineer sẽ implement python code sử dụng những AI lib như huggingface, transformer, pytorch. Những lib này đã cài đặt sẵn thuật toán AI thông dụng như K-Nearest Neighbors, Neural Networks, K-Means Clustering, Transformers
Bài này ASR thì team sử dụng
Transformers của hugging faces , library of pretrained natural language processing
Quá trình train là execute python code ở trên với input là dataset, đội Platform sẽ tạo ra các MLOPs pipeline (SageMaker pipeline) để tự động execute train model mỗi khi có code mới được push lên main repo
Sau khi train model sẽ thực hiện fine-tune ( evaluation), hiểu cách đơn giản là sau khi train một em học sinh xong thì phải test kiểm tra xem nó học hành đến đâu. Và để tránh học vẹt thì phải test nó bằng data khác, nếu trả lời đúng thì thưởng, còn sai thì cốc trán cho tỉnh
Quá trình training, cần phải được monitor and collect metrics, đội dự án đã build lên 1 con
MLFlow Tracker Server dùng để tracking. SageMaker có tích hợp sẵn một built-in tracker server tuy nhiên team tự setup MLFlow server riêng để re-used giữa nhiều dự án ( Vì một số dự án không sử dụng SageMaker)
Rồi cuối cùng là deploy model lên SageMaker Endpoint, quá trình này tương tự như bạn deploy code lên server backend rồi expose API cho user xài
Chi tiết cách viết code để train và fine-tune model thế nào đón đọc phần 2







0 Nhận xét