

Tiếp tục câu chuyện a Grab , giờ là đến anh Uber
History
Nếu như khu vực Đông Nam Á quen xài Grab, thì Uber lại được ưa chuộng ở Âu Mỹ. Anh chị em thích đặt xe thì mở Uber tìm lái xe quanh đây rồi book chuyến ngon bổ rẻ.
Thời kì đầu trước những năm 2014, dữ liệu của Ubder chỉ vài TB, nên việc process data cũng rất đơn giản , chỉ CRUD trực tiếp vào DB, tốc độ process rất nhanh

Về sau Uber ngày càng phát triển ăn nên làm ra, user tăng theo hàm mũ. Data lúc này đã trở thành Big Data, data size tầm 10PB nên mô hình CRUD như trước 2014 đã lỗi thời. Kĩ sư Uber đã re-architected Big Data platform với việc sử dụng Hadoop, CRUD đổi thành ETL jobs để process data vào Data Warehouse

Tuy nhiên, kiến trúc này gặp vấn đề về tốc độ xử lý dữ liệu, nguồn data từ DB sau khi được ETL process phải mất 24 hours mới avaible đến user, data latency quá lớn
Đến năm 2023, thì Uber có 137T user, hoàn thành 9.4 tỉ chuyến xe. Với số lượng user khủng như vậy thì data của Uber cũng lớn không kém, lên tới hàng Petabytes, bao gồm Trip Data, Driver Data, User Data, Traffic Map, dữ liệu giao dịch tài chính, Geospatial Data. Nguồn dữ liệu này yêu cầu phải được process real-time để extract thông tin cho data consumers.
Một hệ thống real-time data processing cơ bản có những thành phần như sau. Uber cũng không ngoại lệ
Collect data —> Stream process --> OLAP, phân tích visualize dữ liệu, make decision
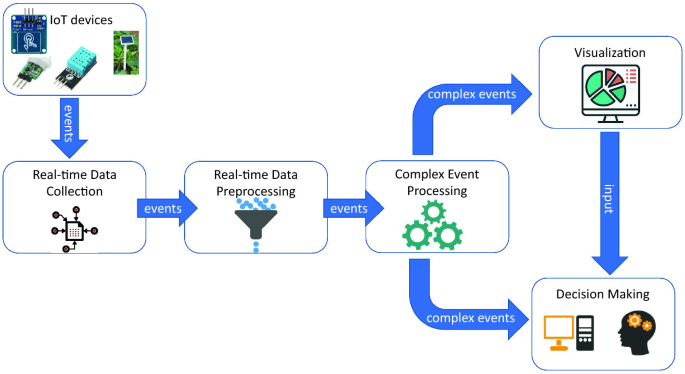
Tuy nhiên, với số lượng user và data lớn như Uber thì có nhiều challenging
Challenges lớn nhất mà Uber gặp phải đó là Scaling, vì lượng real-time data tăng theo hàm mũ nhưng vẫn phải đảm bảo về e2e latency, availaiblity, số lượng user sử dụng dữ liệu cũng tăng, những người này có technical backgroud cũng khác nhau. Challenge thứ hai là Data Fresheness, tức là dữ liệu phải được update liên tục. Ví dụ, khi lái xe đi trên đường thì dữ liệu về traffic, vị trí phải được cập nhật liên tục
Kiến trúc của Thế hệ 1 ,2 không thể đáp ứng được yêu cầu bài toán, kĩ sư Uber đã xây dựng kiến trúc thế hệ 3
Technology Landscape
Đây là overall tech landscape của Uber, được xây dựng trên các platform opensource như Kafka, Flink, Pinot etc…
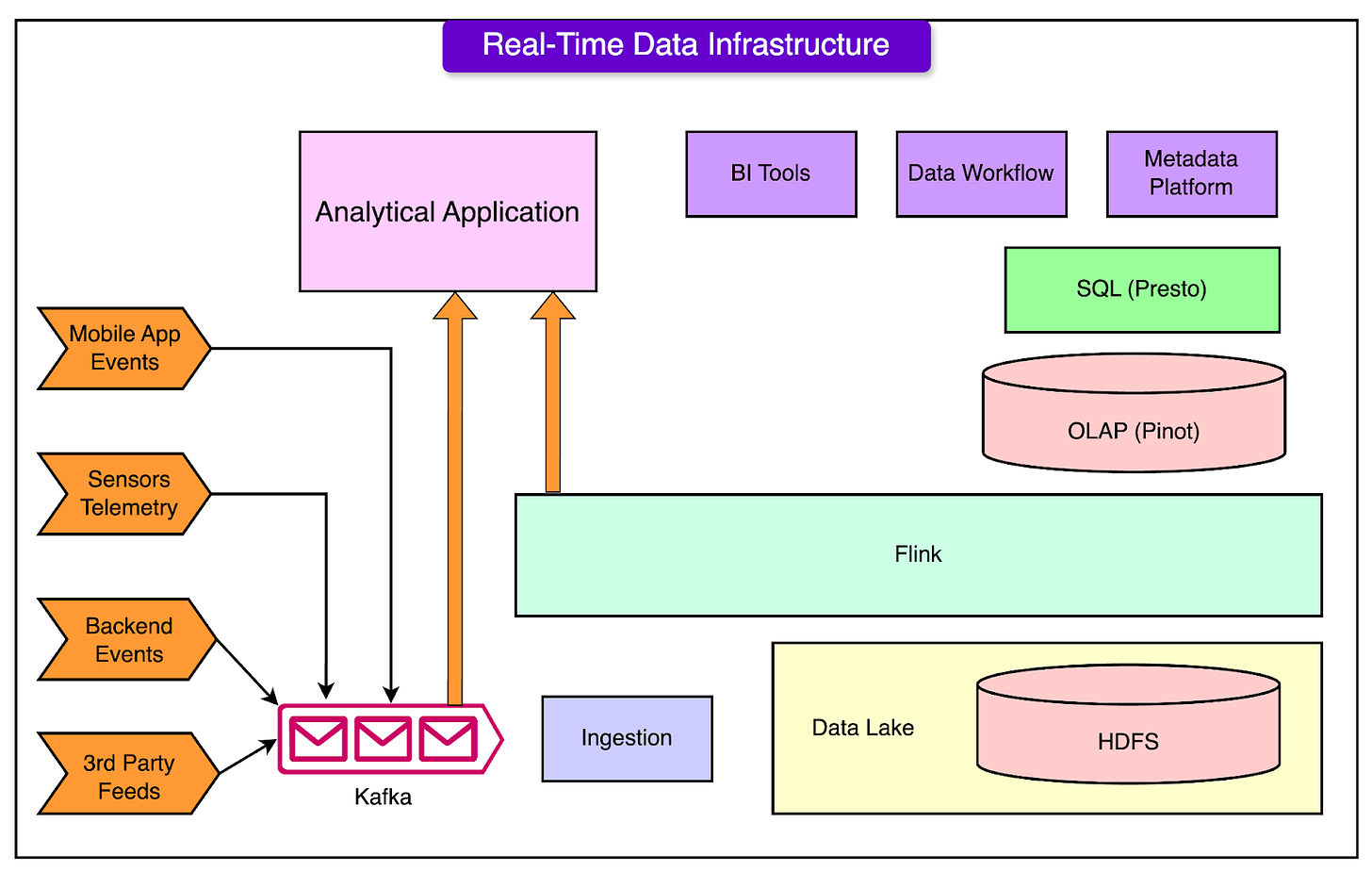
Backbone của Ubder’s data streaming chính là Kafka
Kafka là messaging platform do LinkedIn phát triển sau đó thì open source, được rất nhiều Big Tech ưa chuộng Grab rồi Paypal cũng xài. Thế mới thấy các công ty product đóng góp nhiều cho cộng đồng thế nào.
Ở Uber, Kafka handle vài nghìn tỉ message và hàng PB data mỗi ngày, bao gồm event data giữa lái xe và app, database change logs …
Kĩ sư build nhiều logical cluster Kafka gọi là cluster federation giúp improve scale, bằng cách add thêm nhiều cluster
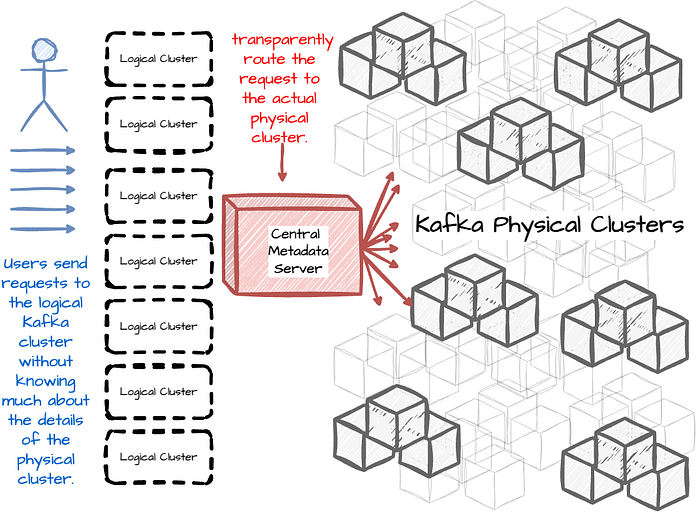
Khái niệm logical cluster Kafka có thể được hiểu thế này.
Khi user truy cập vào server thông qua domain example.com, và họ chỉ biết cái domain đó, còn đằng sau là physical server IP gì, nằm ở đâu không cần care. Logical cluster Kafka cũng tương tự như vậy, user chỉ cần push data vào các topic với naming có sẵn như team1.topic1, team2.topic2 mà không cần care là cluster kafka vật lý nằm ở đâu, cấu hình thế nào. Cluster federation sẽ tự redirect trafict đến cluster Kafka vật lý ,
Dead Letter Queue
Anh em nào làm việc với hệ thống SQS của AWS thì quen với khái niệm này rồi, nếu như downstream system fail trong việc process mesage, thì message đó được đẩy vào DLQ, để re-process sau này,
Consumer Proxy

Việc procedure and consume data to Kafka được thực hiện bởi Kafka-client, là các thư viện developer sử dụng trong app, viết bằng python, c#, Java có hết. Ở uber có cả ngàn application như vậy, khó quản lý. Cho nên thay vì để application consume message trực tiếp từ Kafa, Uber add thêm consumer proxy ở giữa, vào công việc đọc message và route tới endpoint . Tương tự như proxy server của mấy công ty IT áp dụng trong văn phòng. Consumer proxy sẽ tự đẩy message error vào DLQ để re-process sau này
Cross-cluster replication
Data streaming lớn như vậy thì 1 cluster Kafka không đủ, mà phải build multiple Kafka cluster ở nhiều data-center khác nhau
Khái niệm Kafka cluster replication có thể hỏi chatgpt, data được replicate trên nhiều broker, mỗi broker nằm ở zone khác nhau
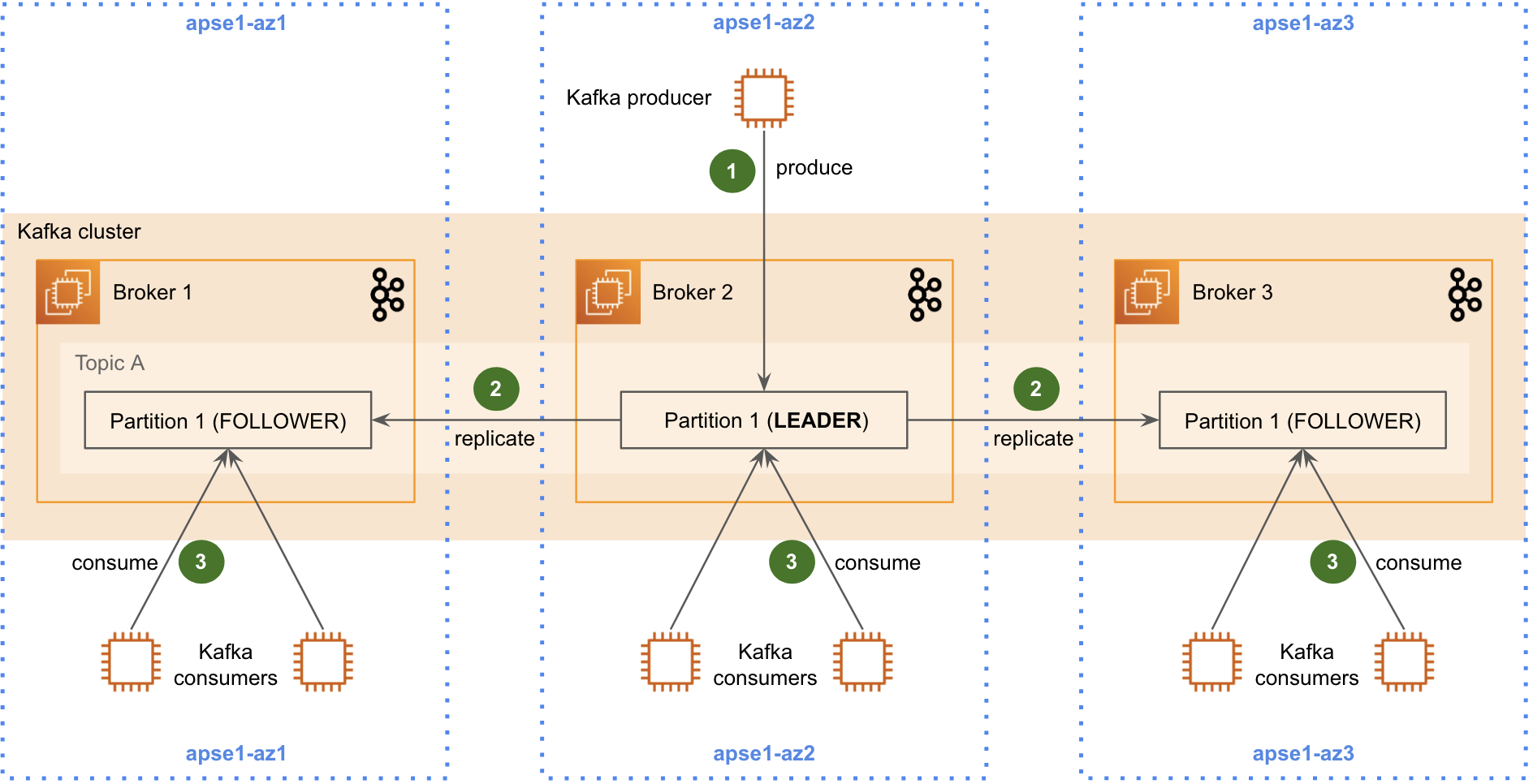
Cái này config của Kafka đã hỗ trợ rồi, google chatgpt cũng có hướng dẫn, gọi là MirrorMaker.
Cách hoạt động của MirrorMaker là consume message từ source cluster rồi re-published lại message lên target, thế là xong replicas, rất đơn giản, ngon bổ rẻ

Tuy nhiên với văn hóa của Big Tech, món MirrorMaker của Kafka bị chê là simple quá, và có nhiều limit khi apply vào bài toán của Uber. Khi số lượng topic và data rate tăng lên nhanh, việc replicas trở nên rất chậm và data bị thất thoát trong quá trình replica
Khi đi sâu nghiên cứu thì Ubder detect được issue gọi là Expensive rebalancing
Như đã giải thích cách hoạt động của MirrorMaker ở trên khá đơn giản là quá trình consumer/producer thông thường. Mỗi consumer trong 1 group consume data từ các paritions đã được assigned sẵn. Đại loại broker giống như anh đi phát cơm, đảm bảo cơm được chia đều cho người nhận, không ông nào được múc quá.
Vấn đề ở đây là consumer thì join leave group liên tục, partition cũng được thêm vào topic. Giống như cơm thì được nhà bếp đem ra, người nhận cơm thì cũng lúc nhiều lúc ít, anh phát cơm phải tự biết liệu cơm gắp mắm để không bị dư cơm, mà không để có người đói. Thế nên Kafka mới cần cơ chế re-balancing, gọi là re-distrubute lại partitions để đảm bảo, mỗi consumer process một lượng partition nhất định. Đo là cách MirrorMaker đang hoạt động, nhưng process rebalacing này quá chậm với lượng data khổng lồ của Uber nên không work hiệu quả, rebalancing không kịp dẫn tơi data loss, consumer kêu khóc thảm thiết vì thiếu message để ăn
Đó là lý do Uber phát triển in-house tool riêng gọi là uReplicator để giải quyết issue, improve performance của Mirror Maker

Uber blog có bài viết riêng về https://www.uber.com/en-VN/blog/ureplicator-apache-kafka-replicator/ tuy nhiên đọc english cũng khó nuốt trôi
Tuy nhiên giaosucan’s blog sẽ tóm tắt một cách đơn giản như sau
Thuật toán rebalance algorithm của Kafka được customize lại run trongHelix controller để assign paritions to each worker. Đại loại giống kiểu cải thiện kĩ năng liệu cơm gắp mắm của anh Kafka broker giúp anh chia cơm nhanh hơn
Kafka consumer/procedure nay được đưa vào uRelicator Worker để thực hiện replica data. Giống như cho một anh cảnh sát giao thông vào phân luồng, sắp xếp cho mấy anh nhận cơm, khỏi dẫm đạp lên nhau, chạy lên vỉa hè
uReplicator Route, virtual group of worker và controller, thường là 3 controller và N worker tùy thuộc vào traffic. Mỗi route chịu trách nhiệm replicate data từ một source cluster sang một destination cluster. Đại loại là tổ chức thành nhiều nhóm phát cơm cho dễ quản lý.
Nhờ có uReplicator, khả năng replicas của Kafka được buff lên level mới, data replica mượt mà, tốc độ




0 Nhận xét