
Coban Team

Anh em hay đi Grab chắc hay đặt câu hỏi theo kiểu 10 vạn câu hỏi vì sao kiểu như
Làm sao mỗi lần book Grab, thì app nó có thể tự tìm kiếm được driver ở gần chỗ mình nhất
Book grab xong, app nó cập nhật được vị trí của driver đang đi đến đâu gần như realtime luôn
Grab đang process data từ hơn 630K driver ở Đông Nam Á, 20TB data mỗi ngày phải xử lý, hạ tầng của Grab chắc phải khủng lắm
Vì sao, vì giăng , sao lại dư thế lày mà không là thế kia
Để xây dựng hệ thống như vậy thì Grab có một team riêng, real-time data streaming platform team. gọi là Coban, tập hợp những infrastructure engineer, SRE , DE. Member của team tập trung ở Đông Nam Á từ Sing đến Thái Lan. Việt Nam cũng tuyển luôn, check hàng tại đây Rất tiếc là chỉ tuyển ở thủ đô, Đà Nẵng chưa thấy có
Nhiệm vụ của team này là thiết kế và vận hành large-scale data streaming platforms trên public cloud, tạo giải pháp GitOps và Gitlab CI để thực hiện resource provisioning… Đại loại team này làm công việc giống như SRE/DEVOPS nhưng chuyên về mảng data platform
Kafka ecosystem
Ecosystem của Grab được build trên Kafka, (Kafka thì quá nổi tiếng rồi) , cứ hỏi ChatGPT là rõ
Lúc đầu Kafka cluster của Grab được deployed trên AWS, nằm trên 1 region Singapore, cross 3 AZs, để đảm bảo avaiability
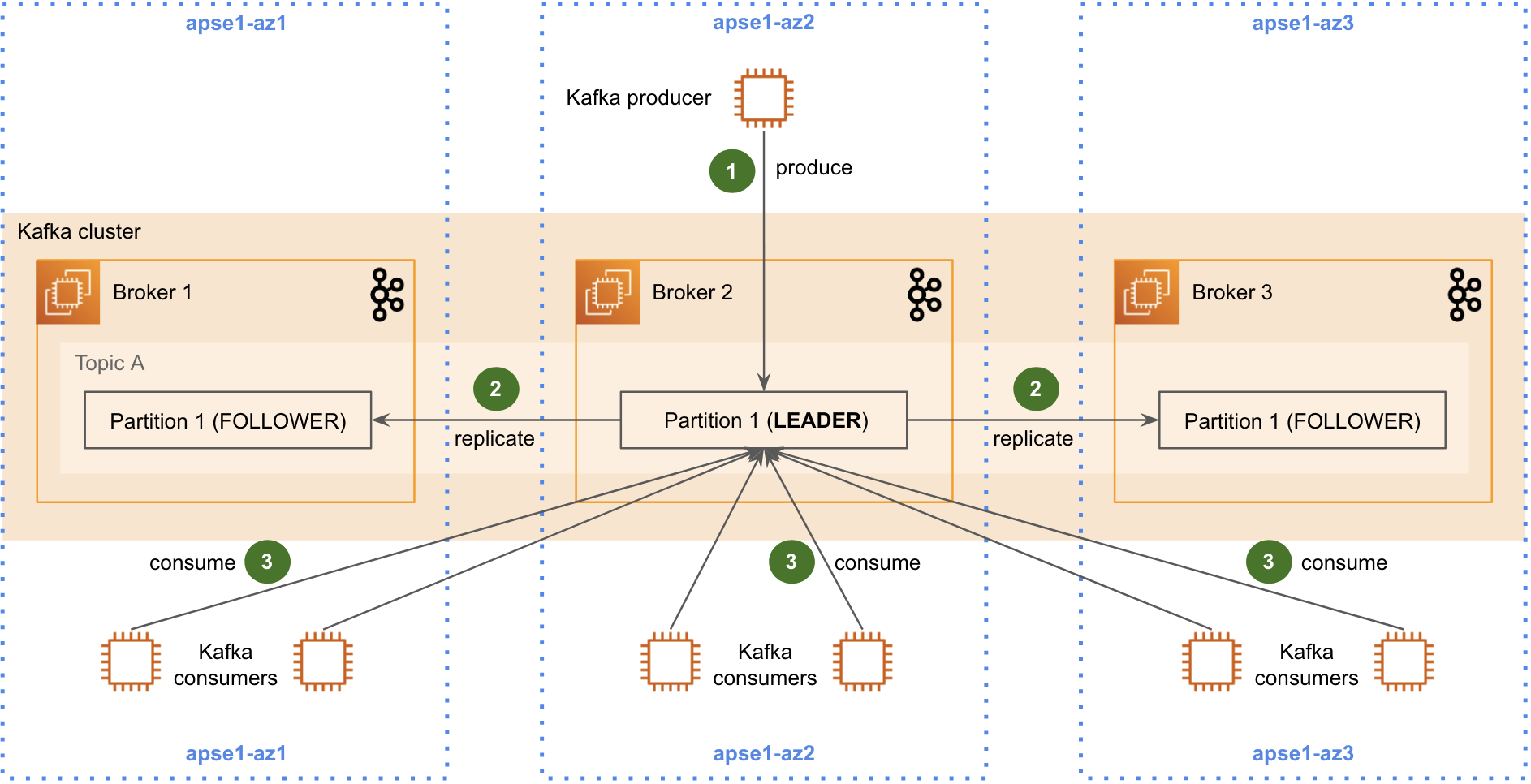
Nói sơ sơ về architect của Kafka cluster gồm producer để produce message vào nhiều topics, rồi được lưu vào các partitions
Data nằm trong partion này sẽ backup vào các partition trên các 3 zones như trên để đảm bảo HA, ko bị thất thoát dữ liệu
Như hình trên Kafka cluster có 1 partition đóng vai trò leader làm nhiệm vụ thực thi đọc và ghi dữ liệu, follower sẽ replica data từ leader.
Nếu nhìn vào mô hình trên, bạn sẽ thấy data transfer giữa 3 zone khác nhau bao gồm data replicas giữa các partition và data transfer từ consumer và leader do Kafka consumer chỉ consume data từ partition leader
Nếu đã biết về AWS network traffic pricing model, bạn sẽ thấy ngay vấn đề ở đây
Phí của AWS ngoài tiền hạ tầng thì một khoản phí khá lớn đó là Data transfer cost

Data transfer giữa các regions, transfer giữa các AZs

và giữa AWS ra ngoài internet

Đối với một công ty làm việc với lượng data khổng lồ như Grab thì chi phí này cứ gọi là xác định luôn. Vì thế CEO Grab đã giao cho Coban team bài toán cần phải xử lý chi phí cost, nếu không thì giải tán
Solution
Cũng may cô thương, nên Kafka ra đời version [2.3], (https://archive.apache.org/dist/kafka/2.3.0/RELEASE_NOTES.html) cho phép consumer có thể fetch data từ partition replicas như dưới
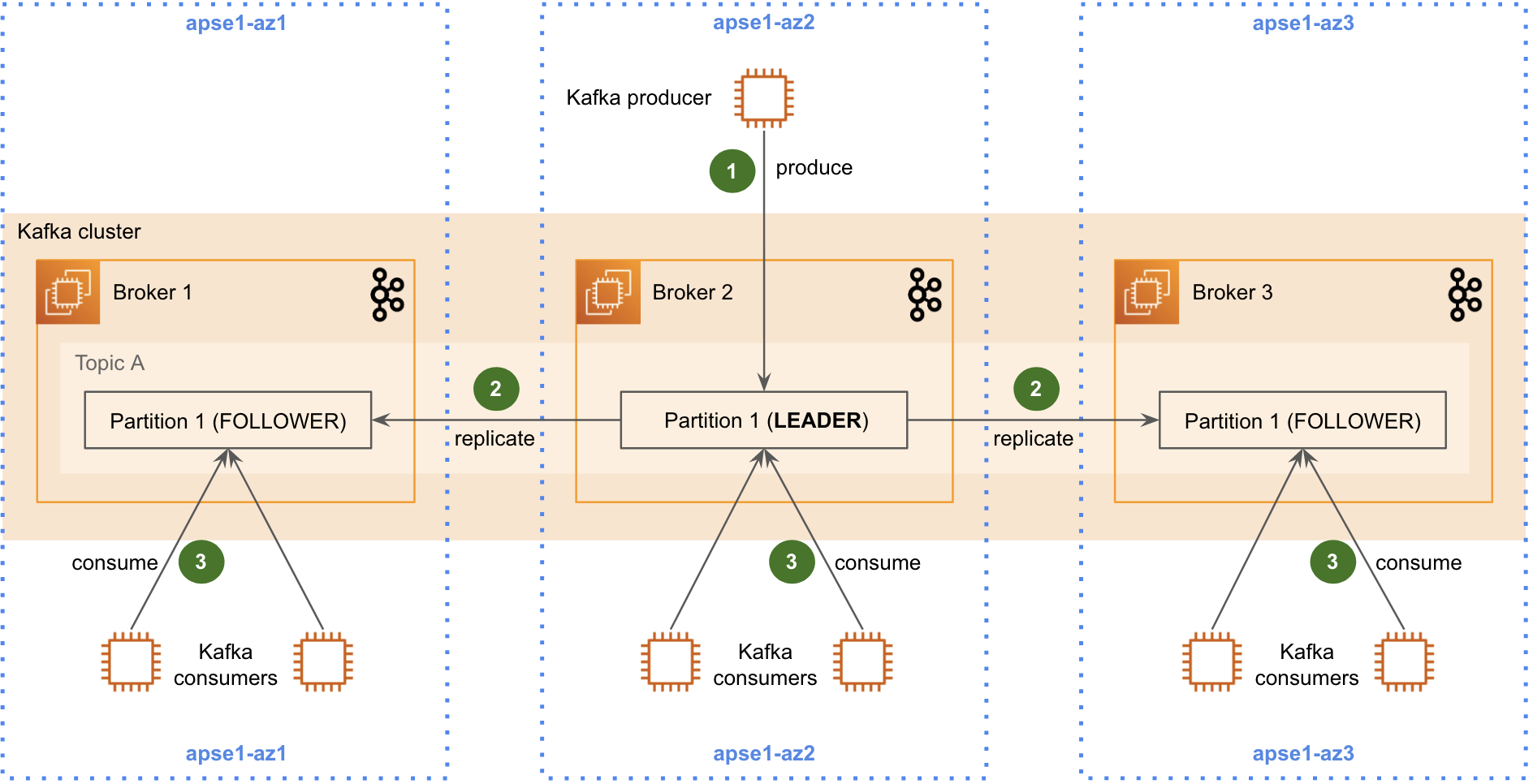
Như vậy là Coban team phải thực hiện việc Upgrade Kafka lên version mới. Tuy nhiên việc upgrade Kafka có nhiều challenging như sau
Cần Zero Downtime để đảm bảo không ảnh hưởng tới người dùng
Prevent data loss trong quá trình upgrade
Trong giai đoạn upgrade, các broker kafka sẽ go down, như vậy các consumer sẽ bị mất kết nối, không thể get data, phải có cơ chế để consumer có thể handle connection error và retry thì broker online
Xử lý Broker/ Leader Skewed issue
Issue này hiểu là thế nào
Xem scenarios sau đây
Như ở hình trên 1 Kafka cluster có 3 broker, mỗi broker chứa 1 vài partition leader, chuyên lo việc đọc/ghi data, mấy partition follower lo việc điếu đóm là replica data

Một ngày đẹp trời, broker 3 tèo, Kafka sẽ promote một follower partition lên làm leader

Ngày khác đẹp trời không kém, broker 1 tèo luôn, lúc này thì toàn bộ các partiton leader dồn hết vê Broker 2

Vậy là anh broker 2 giờ gánh team, toàn bộ request đọc ghi là táng vào anh ý
Sau khi 2 broker hoạt động bình thường trở lại nhưng các leader partitions vẫn nằm trên broker 2

Và điều này dẫn tới skew load, broker 2 bị quá tải, không xử lý được lượng requets từ producer và consumer
và thế là bòm
Coban làm thế nào để giải quyết được như issue trên, đón đọc phần sau



0 Nhận xét