Để tăng cường tính tự động, DevOps team leverage tính năng
Jira Automation. Đây là tính năng rất ưu việt của Jira, tôi thấy nhiều SM đã bỏ qua nó khi quản lý task trên Jira
Jira Automation là gì, cái này đi hỏi ChatGPT là có hàng ngay. Còn hỏi giaosucan’s blog thì đơn giản thế này.
Mỗi khi tạo ticket, bạn phải nhập một đống thông tin như assignee, estimated, point…, attached ticket vào các epic, story…
Chưa kể có team nào muốn request theo kiểu tầu nhanh chỉ ping qua MS team theo kiểu "Chú help anh deploy cái app A, B, C… ", rồi lại phải tạo ticket thủ công rất tốn cơm.
Jira automation sẽ hỗ trợ bạn làm điều đó, tự động cập nhật thông tin, assign ticket vào PIC tương ứng dựa trên những tiêu chí mà SM đưa ra. Đúng kiểu nhất cử lưỡng tiện vừa đại tiện vừa tiểu tiện
Vậy là solution trên đã giải quyết được bài toán của COO đưa ra
Monitoring
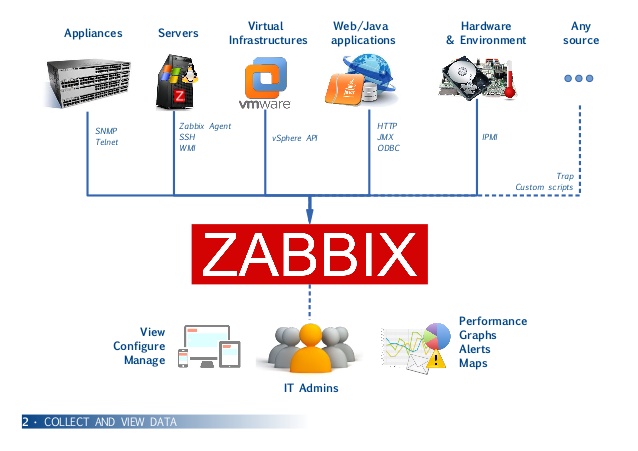
Tiếp theo là việc sử dụng platform monitoring. Trên thị trường có nhiều platform như Datadog, Splunk, Grafana…
Tuy nhiên đây đều làm hàng commercial đắt tiền và tốn kém, với một người sinh ra và lớn lên trong nghèo khó như COO Kosovo, ông đã muốn lựa chọn giải pháp monitoring ngon bổ rẻ hơn, và Zabbix được lựa chọn do free open source.
Em Zabbix được deploy lên 1 Ec2 nhỏ nhỏ t3.medium cho rẻ, các agent installed trên server rồi đẩy metrics về server, anh Sys admin build-up set of dashboard để monitor server, các trigger action
Các
trigger action này send alert cho System admin qua email, sms và MS team alert gọi là media types. Zabbix hỗ trợ khá nhiều media types như Email, Github, SMS (twillo)
Lúc đầu alert được đẩy tới email nhưng thực tế mail box ông nào trong team cũng một đống spam, nên các cụ tắt luôn alert mail cho đỡ phiền. Kết quả nhiều alert bị miss, hệ thống down không có ai xử lý, khách hàng complain. Còn xài
SMS twillo thì ổn hơn, nhưng tốn chi phí hơi nhiều, do tính theo số lượng SMS gửi tới. Tất nhiên với một người sinh ra trong nghèo khó như COO Kosovo, thì việc này không được chấp nhận.
Cuối cùng Ms team alert được apply qua cơ chết Webhook, alert từ Zabbix đẩy thẳng tới MS team channel, vậy là cả team được notify, lại dễ tracking, quan trọng là không mất tiền, đúng kiểu ngon bổ rẻ.
Scaling EKS
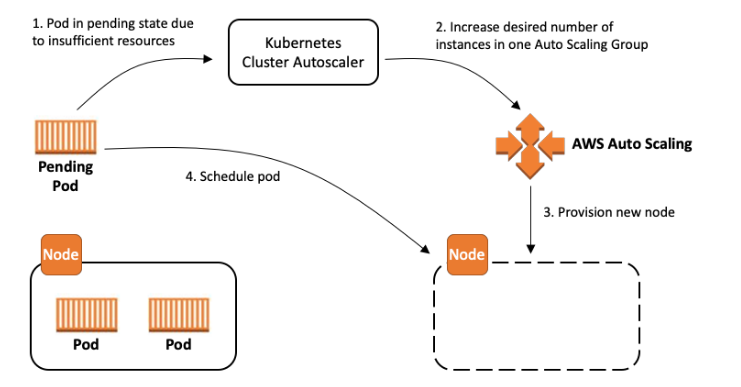
Đây là bài toán khá phức tạp, bởi vị công ty S làm dịch vụ hosting web application. Mà application thì có lúc low workload lúc high workload. Lúc high workload, CPU RAM consumed, hệ thống mà không scaling không hiệu quả thì web down, khách chửi mất uy tín. Nhưng scaling theo kiểu truyền thống dùng EKS autoscaler, loại scaling built in sẵn có của K8s, đại loại là khi high load thì launch thêm node mới, còn low load thì terminate node cũ đi
Tuy nhiên món autoscaler có một số nhược điểm, thời gian terminate và launch node takes time là ảnh hưởng tới latency và scaling time. Thỉnh thoảng bị over-provisioning, tức là provisoning những node side vượt quá so với nhu cầu, đại loại là giống như đem hoa hậu báo tiền phong ra phục vụ xe ôm, thợ hồ, tốn chi phí không cần thiết. Và COO, vâng một người sinh ra từ vùng đất chiến tranh như KOSOVO không thích điều này
Ngoài ra, việc scaling của autoscaler dựa vào một số metrics cơ bản như CPU, Memory. Tuy nhiên thông số này cũng không phải lúc nào cũng chính xác, dẫn tới autosaler không đưa ra quyết định scaling chính xác
Tóm lại là phải có giải pháp scaling thông minh, optimize cost hơn.
Cuối cùng sau rất nhiều xung đột giữa Nga và U cà na, Kosovo và US thì giải pháp mới được lựa chọn
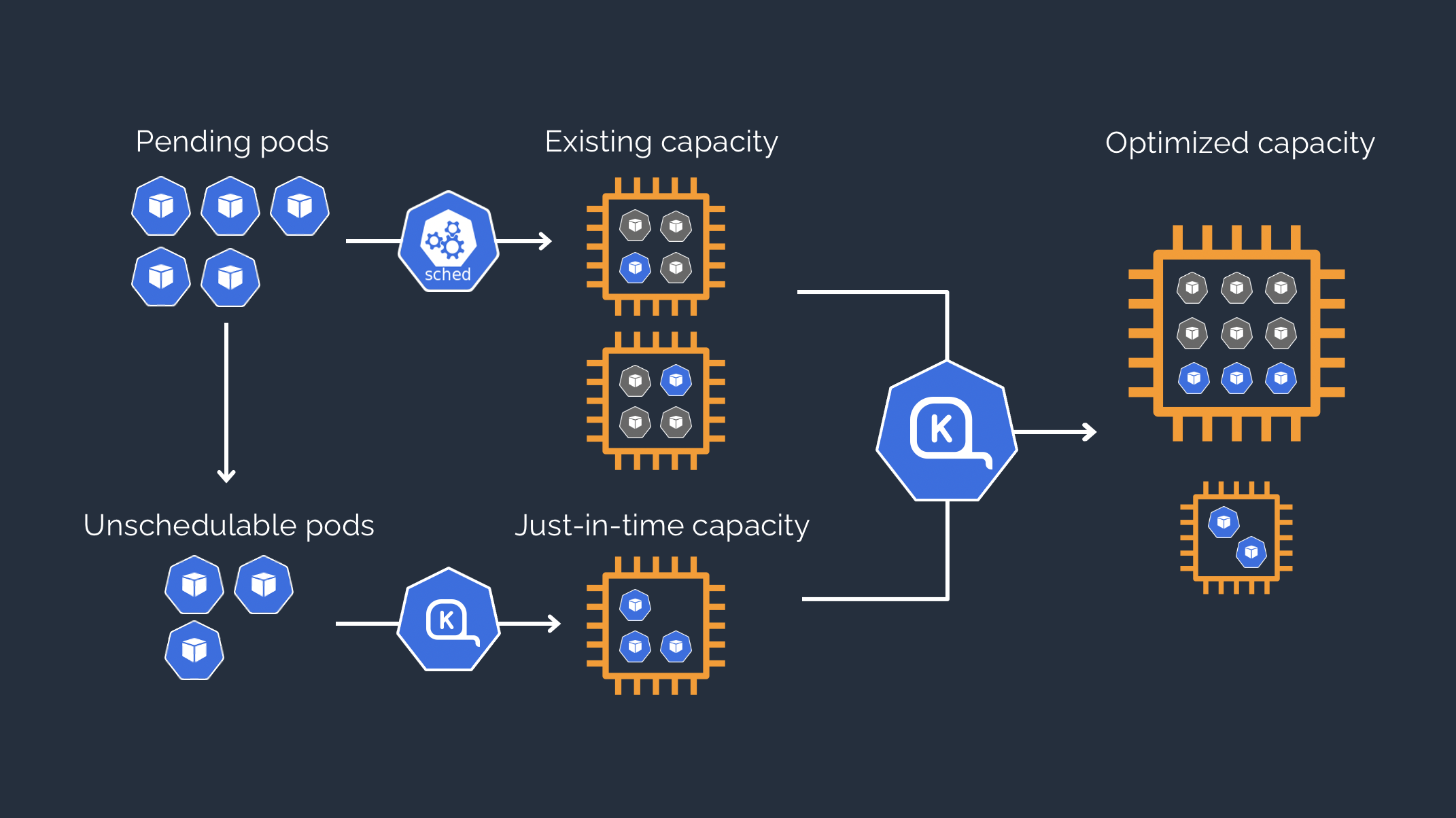
thay thế Autoscaler built in của EKS bằng
KarpenterMột open source platform để thực hiện autoscaling trên EKS
Vậy Kapenter hoạt động thế nào, team DevOps Đông ÂU áp dụng nó ra sao , đón đọc phần sau






0 Nhận xét