Trong lĩnh vực y tế, có một khái niệm gọi là Medical Image Segmentation, chẩn đoán bệnh và phân tích trong y học với các hình ảnh chụp X-quang hay ảnh chụp cộng hưởng từ (MRI). Hiểu đơn giản là khi bệnh nhân chụp X-Quang xong, bác sĩ ngồi xem ảnh chụp rồi phán đoán “Khối u nằm chính xác ở đâu, hình dạng ra sao và chiếm diện tích bao nhiêu milimet.”* Cái này làm bằng cơm và phụ thuộc nhiều vào kinh nghiệm trình độ của bác sĩ
Semantic Segmentation
Và thế là AI được ứng dụng để làm thay công việc của bác sĩ, nhanh hơn chính xác cao hơn
Cách hiểu đơn giản của Semantic Segmentation là
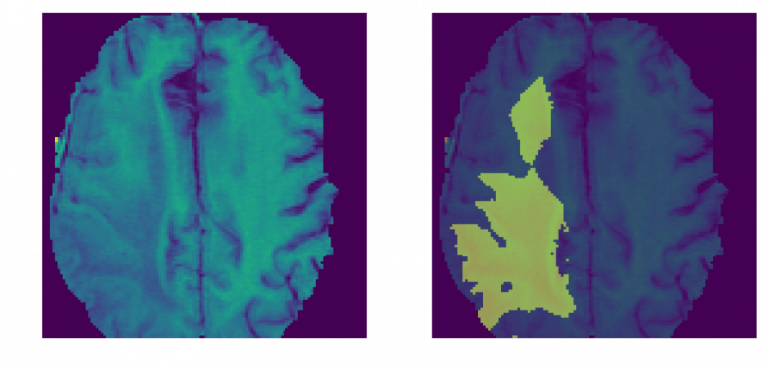
Ví dụ trên là hình ảnh con đường với xe cộ, máy tính sẽ tô màu oto là màu đỏ, đường là màu hồng, nhà cửa là màu vàng. Đây là một cách máy tính gán label cho từng object trong hình ảnh
Các pixel thuộc về “đường” sẽ được phân loại vào lớp “đường” (màu hồng), pixel thuộc về “car” được gán nhãn là “car” (màu đỏ)
Trong y tế, cách gán label trên áp dụng như sau
Bác sĩ nhìn vào “bản đồ màu” này sẽ biết ngay diện tích khối u chiếm bao nhiêu phần trăm diện tích não mà không cần phải tự mình dùng mắt thường để đo đạc từng li một trên ảnh đen trắng mờ ảo
Tóm lại, Semantic Segmentation giống như dùng bút màu highlight chỗ quan trọng trong văn bản, mở lên phát biết ngay chỗ nào cần để ý
Đội dự án X triển khai AI để thực hiện bài toán tương tự cho khách hàng là một công ty y tế. Công ty có lượng dữ liệu lớn là những ảnh DICOM (Digital Imaging and Communications in Medicine),
Nhiệm vụ của team là sử dụng nguồn dữ liệu này để train and deploy một AI model giúp bác sĩ có thể nhận dạng cấu trúc xương, những bất thường như khối u, xương gãy, vật thể lạ trong xương, v.v.
DICOM là gì
Đây là loại ảnh chuyên dụng trong lĩnh vực y tế
- Phần Hình ảnh: Ảnh có độ phân giải và độ sâu màu cực cao (giúp bác sĩ thấy được những tổn thương mờ nhạt nhất).
- Phần Header : Chứa tên bệnh nhân, thông số kỹ thuật của máy quét, và đặc biệt là tỉ lệ xích thực tế (để AI hoặc bác sĩ có thể đo được chính xác khối u dài bao nhiêu mm).
Vì DICOM là loại dữ liệu cấu trúc phức tạp như vậy nên việc sử dụng trực tiếp loại dữ liệu này để train AI là không hợp lý
Cần phải có 1 bước tiền xử lý để Convert DICOM → NIfTI
Hãy tưởng tượng DICOM là một cuốn album ảnh, mỗi trang là một lát cắt cơ thể và trên mỗi trang đều ghi tên bệnh nhân, ngày chụp.
NIfTI giống như việc bạn lấy tất cả các tấm ảnh đó ra, dán chồng chúng lên nhau để tạo thành một khối gạch 3D duy nhất. Bạn vứt bỏ những thông tin rườm rà (tên tuổi, bệnh viện) và chỉ giữ lại đúng “cái xác” 3D để máy tính tính toán cho nhanh.

Loại dữ liệu NlfTI này mới được dùng để train AI model
Tưởng tượng NlfTI giống như một chiếc hộp đựng thực phẩm đóng gói sẵn. Bên ngoài vỏ hộp ghi các thông số (Hạn sử dụng, thành phần, trọng lượng) và bên trong là thực phẩm thật sự
Phần header giúp máy tính hiểu được khối dữ liệu 3D này là gì, thông tin quan trọng là
Coordinate System (Hệ tọa độ): Nó chứa các ma trận để định vị xem đâu là bên trái, bên phải, phía trên hay phía dưới của bệnh nhân trong không gian 3D.
Affine Matrix: ánh xạ các tọa độ từ “vị trí trong file” (voxel coordinates) sang “vị trí trong thế giới thực” (world coordinates - mm). Hiểu 1 cách đơn giản nó giúp bạn nhìn thấy hình ảnh ở đúng góc độ, ko bị lộn ngược, hoặc xiên xẹo
Data Block là nơi chứa dữ liệu hình ảnh thực sự, là một array number, mỗi con số thể hiện độ sáng tối. Trong NIfTI, dữ liệu này được xếp liên tục kiểu này
[100, 105, 110] <- Hàng 1
[120, 255, 125] <- Hàng 2 (Số 255 có thể là một điểm sáng trắng)
[110, 115, 100] <- Hàng 3
Chính vì cấu trúc “phẳng” và liên tục này mà các thư viện như Numpy có thể đọc và xử lý cực nhanh, vượt xa việc phải mở từng file DICOM lẻ tẻ.
Team AI dùng thư viện dicom2nifti để gộp hàng trăm file DICOM thành 1 file NIfTI duy nhất
Sau khi có dữ liệu NlfTI, bây giờ mới đến phần AI xử lý. Đội dự án sử dụng nnU-NET để thực hiện training
nnU-Net
Cái này thuần tech thì quá hard core, còn giải thích kiểu bình dân của giaosucan’s blog thì thế này
Ví dụ, bạn có công thức nấu ăn món cá, đầu vào của bạn là cá, dù là cá tươi hay cá đông lạnh, cá ươn, cá blo bla, một AI bình thường cứ áp dụng máy móc công thức nấu ăn trên, kết quả là ngon dở mang tính hên xui. Và mỗi lần train rồi test, AI engineer lại phải lọ mọ điều chỉnh tham số training để đảm bảo ra được kết quả ngon nhất
Còn với nnU-NET, nó giống như một master chef, ông ta tự nhìn vào nguyên liệu (Dữ liệu), nếu cá tươi thì ông hấp, nếu cá đông lạnh thì ông kho, gia giảm nhiệt độ, gia vị tuỳ thuộc vào nguyên liệu. Ông ta tự thay đổi cách làm để luôn cho ra món ăn ngon nhất.
nnU-NET nó giống như master chef, khi đưa cho nó một đống ảnh chụp cơ thể người (dưới dạng file NIfTI), nó sẽ:
- Tự học cách phân biệt các bộ phận mà không cần bạn phải chỉnh bất kỳ thông số kỹ thuật nào.
- Tự vẽ ra một bản đồ màu (Segmentation) cực kỳ chính xác.
Đảm bảo kết quả tốt nhất có thể, vì nó đã tự thử nghiệm hàng ngàn cách cấu hình khác nhau trước khi đưa ra bản thiết kế cuối cùng.
Như vậy AI engineer sẽ không phải mất công ngồi tinh chỉnh tham số như đối với AI thông thường
Cái tự chỉnh thông số đó là phần Automatic Configuration trong architect của nnU-NET
Nó phân tích các thuộc tính dữ liệu (độ phân giải, kích thước khối, dung lượng VRAM GPU của bạn) và tự động tính toán ra các tham số tối ưu. Ví dụ như Patch Size & Batch Size: Nên cắt ảnh thành các khối bao nhiêu (ví dụ
128×128×128) và đưa bao nhiêu khối vào huấn luyện cùng một lúc.
Còn sau phần Automatic Configuration thì là U-NET cơ bản
Cách U-NET hoạt động cũng y hệt như cách con người xử lý
Ví dụ, khi bạn gặp một em gái, thì việc đầu tiên sẽ nhìn tổng thể về em đó như cao ráo, xinh đẹp chứ không chằm chằm vào một cái nốt ruồi hay sợi tóc ngay lập tức.
Cách thực hiện: Bạn nhìn từ xa, lướt qua những đường cong tổng thể để xác định "vòng nào ra vòng nấy". Đàn ông đích thực nhìn ngực đầu tiền
Mục đích: để hiểu ngữ cảnh. Bạn xác định được đâu là gương mặt thanh tú, đâu là đôi chân dài, tóm lại là nhìn có ngon hay ko
Trong AI: Nhánh này thu nhỏ hình ảnh để nắm bắt cấu trúc lớn. Nó xác định: "Đây là vùng nhạy cảm cần quan tâm, đây là vùng nền không quan trọng".
Cái trên gọi là Encoder ( nhìn tổng thể)
Sau khi đi tổng thể rồi, thì mới đến phần chi tiết (Decoder) Soi những bộ phận nhẩy cảm như hàng họ, vùng cấm, rồi highlight nó lên (Semantic Segement)
Trong AI: Nhánh này phóng to ảnh lại, tỉ mỉ "tô màu" cho từng pixel để ranh giới của các cơ quan phải thật mượt mà, chính xác.
Tất nhiên mải ngắm ngực quá thì đôi khi bị xao nhãng, chỉ để ý đến ngực to, dẫn tới vui chơi quên nhiệm vụ chính là phân tích tổng thể về cô gái chứ ko phải chỉ soi mỗi ngực, cái này gọi là Skip Connections, như nhắc nhở AI tập trung vào
Training
Team Infra build 1 AWS Batch dùng instance GPU g6e.16xlarge để chạy training jobs, dữ liệu đầu vào là tập ảnh NlfTI đã convert ở trên, khách hàng cung cấp một lượng data đủ lớn để team chạy training, mỗi lần train mất 7 ngày, trained model lưu trên S3 để phục vụ cho phần interfere sau này
nnU-NET quét khoảng 1000 epod
Cách nnU-NET học thế nào
nnU-Net không học vẹt. Nó học theo kiểu “thử và sai”:
4. Giai đoạn đầu (Đoán mò): AI nhìn vào ảnh và tô màu đại một vùng. Sau đó nó so sánh với “đáp án” (mặt nạ do bác sĩ vẽ).
5. Tính toán lỗi (Loss Function): Nó tính xem mình tô lệch bao nhiêu milimet, sót bao nhiêu pixel.
6. Tự điều chỉnh (Backpropagation): Nó quay ngược lại các nơ-ron thần kinh bên trong để điều chỉnh các “nút thắt” toán học, sao cho lần sau dự đoán chính xác hơn.
7. Tăng cường dữ liệu (Data Augmentation): Để AI không bị “học tủ”, nnU-Net sẽ tự động xoay ảnh, làm mờ ảnh, bóp méo hình dạng… để bắt AI phải nhận diện được khối u trong mọi tình huống khó khăn nhất.
Sau 7 ngày training, kết quả chạy test interfere khá ấn tượng, độ chính xác trong nhận dạng y tế đạt trên 80%







0 Nhận xét