

Câu chuyện
Anh A làm Dev IT cho công ty Fxxx đã mười năm, cả đời cống hiến đóng góp công sức vào bao dự án. Nhưng mỗi năm tăng lương CHE chỉ đủ ăn và chống lạm phát. Con khóc vợ kêu, cuộc sống đầy khó khăn. Vì hoàn cảnh mưu sinh, anh phải làm nghề tay trái non-tech, là kinh doanh cho thuê Village, biệt thự. Mỗi tháng mong kiếm được đồng ra đồng vào về nuôi gia đình.
Thế là anh mua 1 căn village biển và mấy cái chung cư rồi lên Airbnb lập profile để kiếm khách. Từ đó sáng anh lên văn phòng ngồi code, tối về vào Airbnb lập listing quảng cáo đợi booking, cũng chỉ mong cải thiện thu nhập, bát cơm thêm miếng thịt . Nhưng rồi, càng tìm hiểu, anh thật sự choáng ngợp trước data infrastructure khổng lồ của Airbnb
Airbnb có khoảng 150M+ user (khách đặt phòng) , 7.7M listing trải dài 100K thành phố trên thế giới và 5M+ host (chủ nhà cho thuê).
Cứ 1s có 6 guest check-in vào Airbnb listing
Mỗi 1 listing lại chứa nhiều thông tin
Host user profile: Thông tin về chủ nhà tên tuổi, số lượng review, số lượng listing mà host owner
Listing profile: Title ví dụ Family Friendly Resort Apt 2BR/Private Beach/Pool, description,
vị trí, nhà có những đồ đạc gì đi kèm như tivi, tủ lạnh, bồn tắm. Service như massage, xông hơi, spa thư giãn
…
Những dữ liệu do user tự cập nhật, được Airbnb collect, gọi là raw data. Khi các data này được xử lý bởi tools như Spark hay Kafka thì trở thành derived data. Ví dụ căn cứ vào data về số lượng review, guest rating, airbnb xử lý tính ra được rating trung bình của listing 4,.97, 4.98
Số lần truy cập, user activity (raw data) để Airbnb thống kê xử lý thành metrics (derived data)
Tóm lại raw data là data được collect chưa xử lý, còn derived data là dữ liệu đã được hệ thống Airbnb process, nhào nặn, nắn bóp mà thành
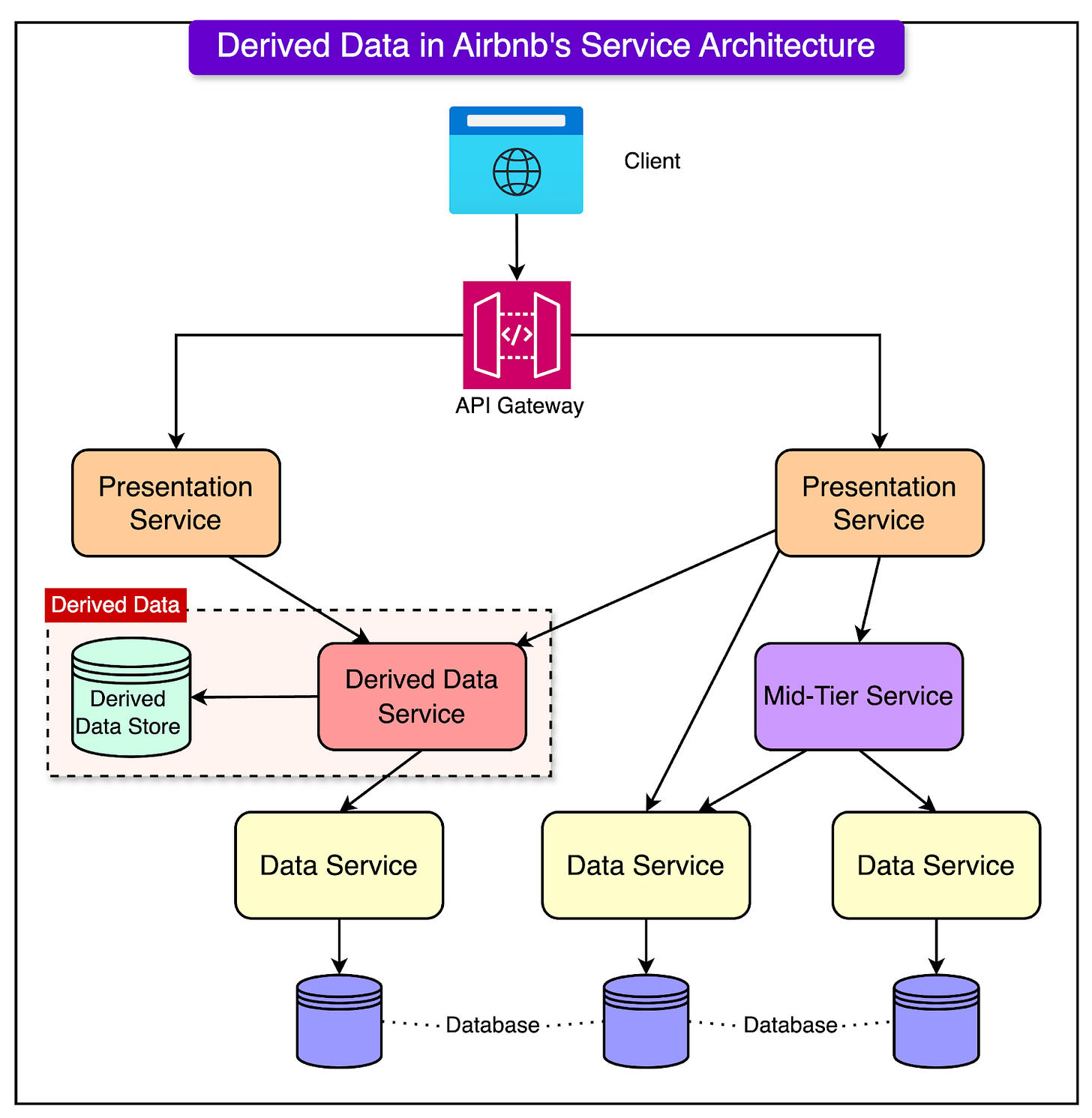
Derived data này khổng lồ hàng Petabyte và cần phải tìm quản lý hiệu quả
Bussiness requirement
Derive Data Storage phải đảm bảo High Avaiability , truy cập anytime không bị interrupt. Scale để đáp ứng lượng data ngày một lớn của Airbnb
Và điều tối quan trọng là low latency. Tưởng tượng vào mùa cao điểm giáng sinh lễ tết, số lượng khách booking tăng đột biến, nhà nghỉ cháy phòng, mà một booking process cả tiếng mới xong thì hỏng hết cơm gạo
Nói về data thì ngoài kiểu data SQL truyền thống thì Key-Value stored (No-SQL) được sử dụng nhiều trong hệ thống Big Data, chi tiết Key-value data thì Google, ChatGPT
ví dụ thông tin về một listing trên airbnb dạng Key-value store, bao gồm id , chủ nhà, title vị trí, ngày còn phòng
{
"name": "Cozy Studio in Downtown",
"host_name": "Alice Johnson",
"city": "New York",
"price": 120,
"room_type": "Entire home/apt",
"minimum_nights": 2,
"number_of_reviews": 56,
"availability": 200,
"location": {
"latitude": 40.7128,
"longitude": -74.0060
}
}
Với hàng triệu Listing thì lượng data này yêu cầu
Phải scale tới petabytes
Support builk load (upload theo batch)
Low latency reads (<50ms p99)
Multi-tenant storage để có thể dùng chung với nhiều team, nhưng phải đảm bảo data privacy and compliance, team A không access data của team B
Solution
Một giải pháp được Airbnb xem xét là sử dụng RocksDB, Key-Value storage platform viết bằng C++, phát triển bởi FacebookKiến trúc của RocksDB

Data lưu trong RocksDB vào sst file format, gọi là Static Sorted Table gồm Data section dùng để lưu data dạng Key Value , thêm một section index để lưu vị trí của key để thực hiện searching
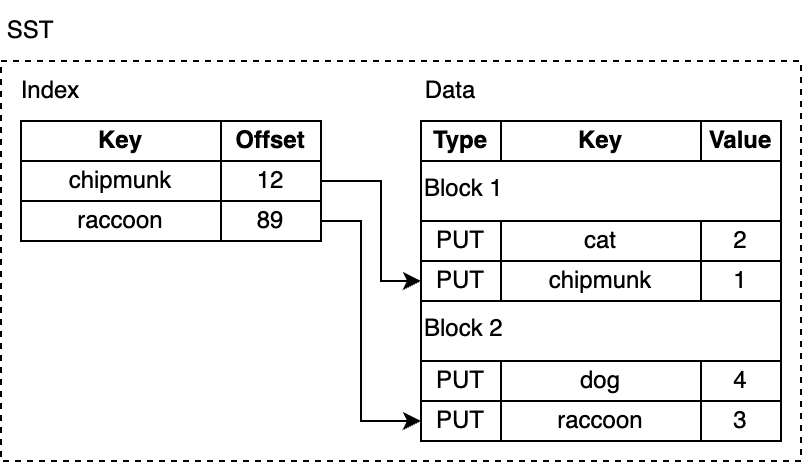
Ví dụ muốn tìm key chipmunk thì index offset 12 ứng với block 1, vậy search trong block 1 là ra
Như vậy việc build những data pipeline support RocksDB khá phức tạp, lại viết bằng C++, Airbnb không có nhiều kĩ sư giỏi về C++
Một yêu cầu nữa của Airbnb với data là khả năng Horizontall Sharding, hiểu là distribute data ra nhiều data nodes, sau này có thêm data thì scale out bằng add thêm shard là xong. Hỗ trợ đọc/ghi data song song tăng được performance
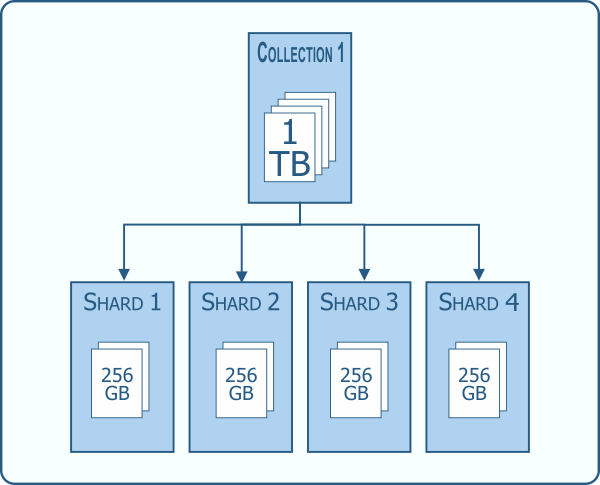
RocksDB không có chức năng built-in horizontall sharding, nên platform này bị loại
Lựa chọn thứ 2 của Airbnb là Hbase, Apache platform Bigdata rất thông dụng, nhưng được customize lại theo business need của Airbnb
Tương tự như RocksDB , storage format của Hbase là HFile, key-value store của hbase, loại format này được Airbnb sử dụng để lưu data
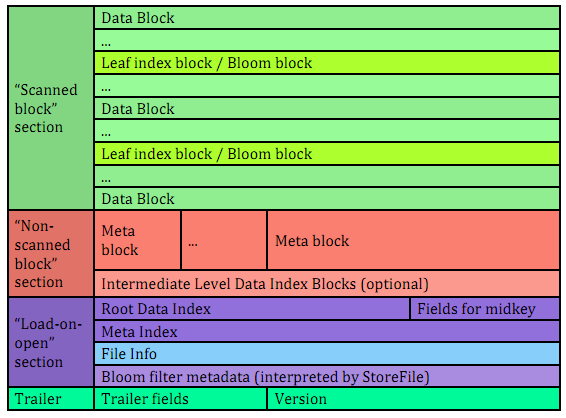
Thực sự cách mô tả HFile format trên Google, ChatGPT quá khó hiểu, ngay cả tech cũng không nuốt trôi nổi
Cố gắng giải thích đơn giản thế này
Scanned Block là nơi lưu data dạng key-value, khi service tìm kiếm dữ liệu, thì nó truy cập vào vùng này. Ví dụ thông tin về listing, id, rating dạng key-value được lưu ở đâu
Non-scanned là vùng lưu meta data của data ở trên, là lưu mô tả về dữ liệu ở Scanned Block
Ví dụ như listing data được tạo ra lúc nào, ông nào tạo ra nó, ai sửa đổi lần cuối
Trailer Lưu thông tin của toàn bộ sections, khi đọc HFile, section này được đọc đầu tiên. Giống như trước khi đi xem phim và lướt trailer để ngó thử phim như thế nào
“Load-on-open” section Lưu block index và thông tin file
Để xử lý dữ liệu trên HFiles, Airbnb tạo ra HFileService, data batch-processing
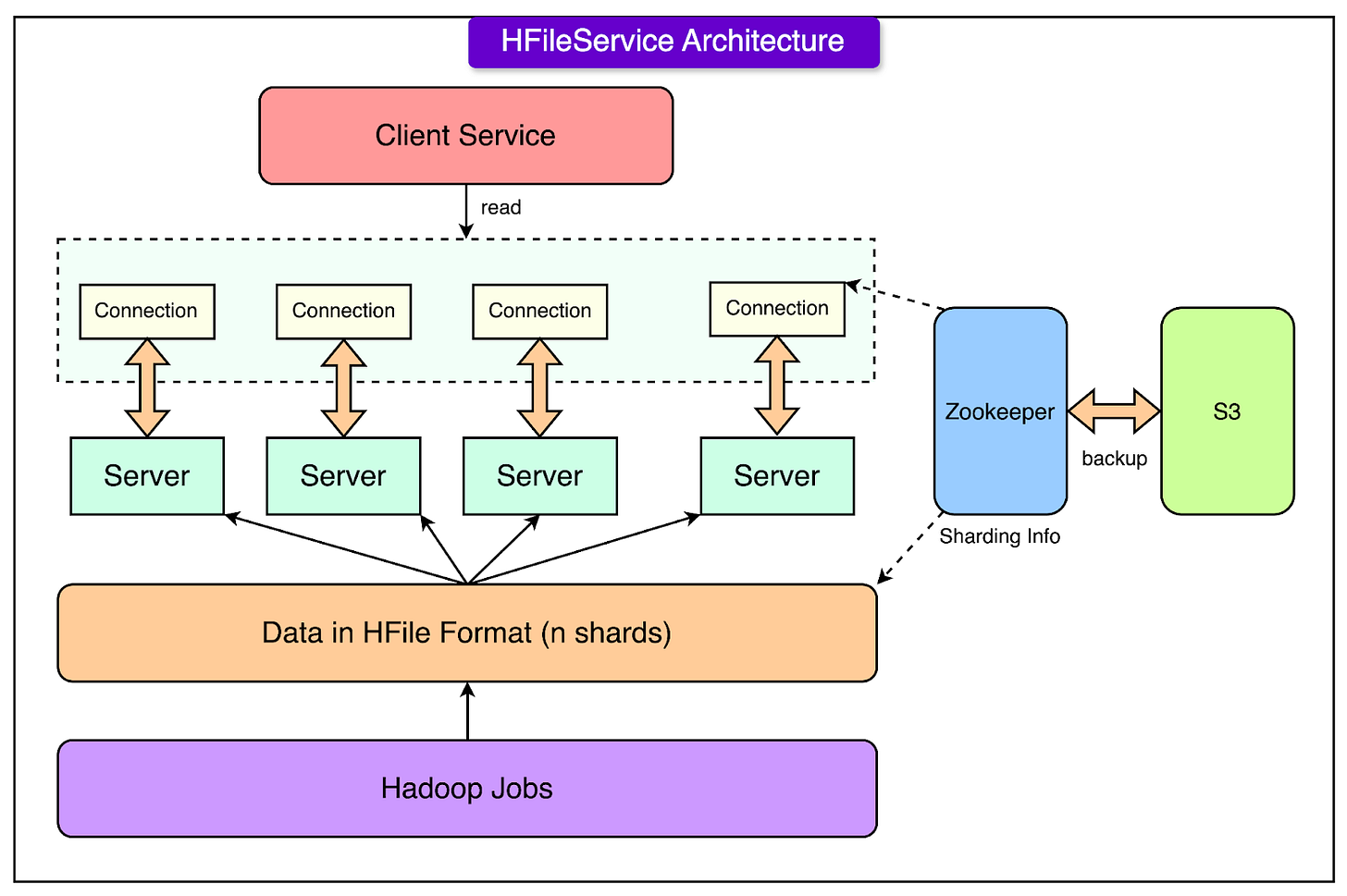
Hadoops jobs chạy daily để thực hiện Batch raw data processing, convert raw data ghi vào HFile format
Dữ liệu được chia theo sharding, lưu trong nhiều server, quản lý bởi zookeeper đọc dữ liệu từ HFiles, backup vào S3 trả về cho Client Service
Tuy nhiên HFileService chỉ đọc data nhưng không update real-time. Hadoop jobs chạy batch daily nên nếu có update data , thì phải chờ next day để cập nhật data vào HFiles, lúc đó Client Service mới read được latest data
Tóm lại dữ liệu không real-time
Vì thế Airbnb đã xây dựng hệ thống mới Nebula , lấy tên nhân vật trong Avenger để giải quyết việc batch-processs data realtime
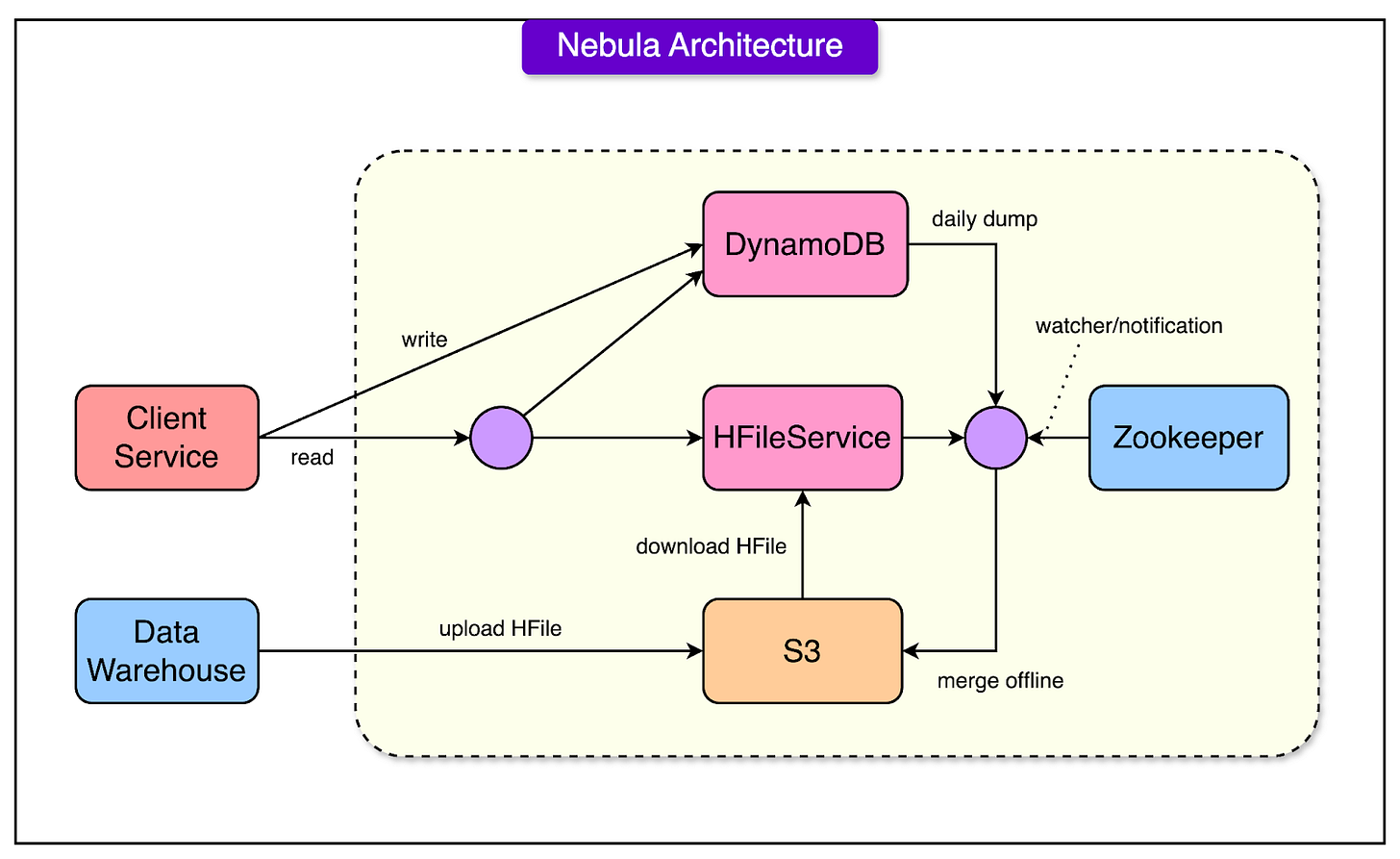
Việc daily data-batch processing vẫn được thực hiện bởi HFileService như cũ, add thêm DynamoDB as dynamic data store, NoSQL của AWS
Theo diagram trên thì Client Service có thêm chức write real-time data vào DynamoDB, daily jobs sẽ dump data và offline store HBase, chức năng read sẽ đọc từ DynamoDB for realtime data và HFileService for offline data
Nhìn như hình trên, mỗi khi client service cần đọc data, Nebula sẽ merged data từ Dynamodb và HFiles service để trả về latest data
Tuy nhiên Nebula có nhiều challenging
Airbnb SRE phải quản lý 2 hệ thống riêng biệt là DynamoDB và HFileService dẫn tới Operational Overhead, rất phức tạp, nhất là đoạn Merge data từ DynamoDB và HFileService dẫn tới data latency do merge process mất thời gian xử lý, và tốn computing resources
Scalability Challegnes: Airbnb data grow up rất nhanh, việc scale Nebula để handle lượng traffic và growing dataset trở nên phực tạp, data processing ngày càng chậm
Vậy Airbnb làm thế nào để giải quyết, nhớ thả tìm, booking listing của tác giả để đón đọc bài mới



0 Nhận xét